

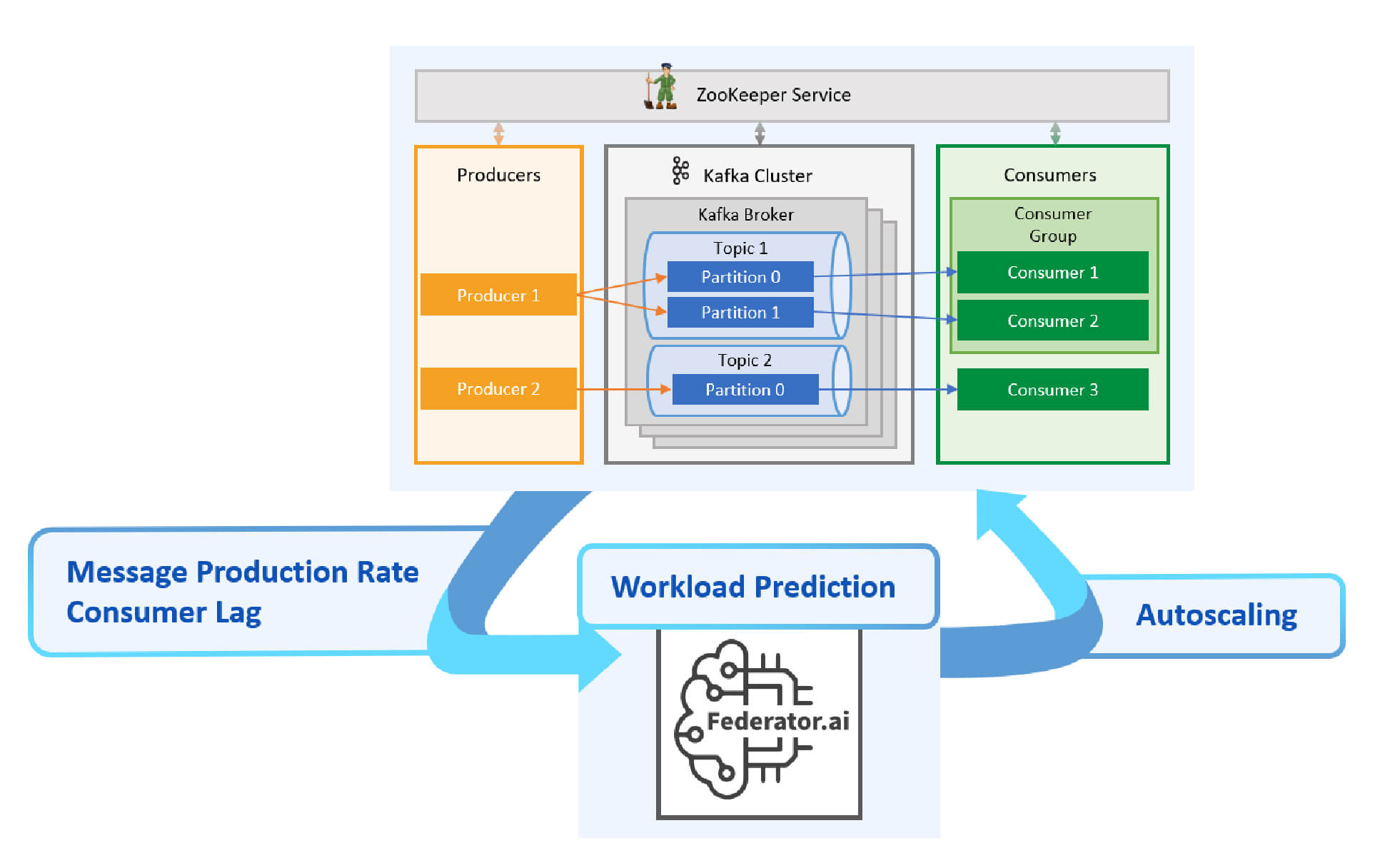
In a Kafka-based application, messages for specific topics are generated from some producers, and sent to the Kafka brokers. The brokers perform required replications and distribute messages to the consumers of the respective topics. After receiving messages from the brokers, a consumer will perform some tasks and let the brokers know the messages have been committed (or consumed). The zookeepers maintain the offset of the last message sent by a producer for a topic, and the offset of the last committed message notified by a consumer for a topic. When there is a burst of messages received by the brokers, the messages will be stored in the queues longer if a consumer cannot process the messages fast enough, affecting overall application performance. In order to handle the dynamic nature of message production rate, HPA or Horizontal Pod Autotscalling of the Kafka Consumers is used to scale the number of Kafka Consumers so that the production and consumption rates of a topic are matched while using a reasonable number of consumer replicas (minimize resource costs). At the same time, HPA also needs to maintain a low latency of processing messages, which is a KPI or Key Performance Index of Kafka Consumers. In particular, we are calibrating the number of replicas with the following trade-offs:
A Kubernetes HPA controller is a controller that can determine the number of pods of a deployment, a replica set, or a stateful set. The HPA controller measures the relevant metrics to determine the number of pods required to meet the criteria as defined the HPA’s configuration, which is implemented as API resource with information like the desiredMetricValue. A native HPA controller supports the following types of metrics to determine how to scale:

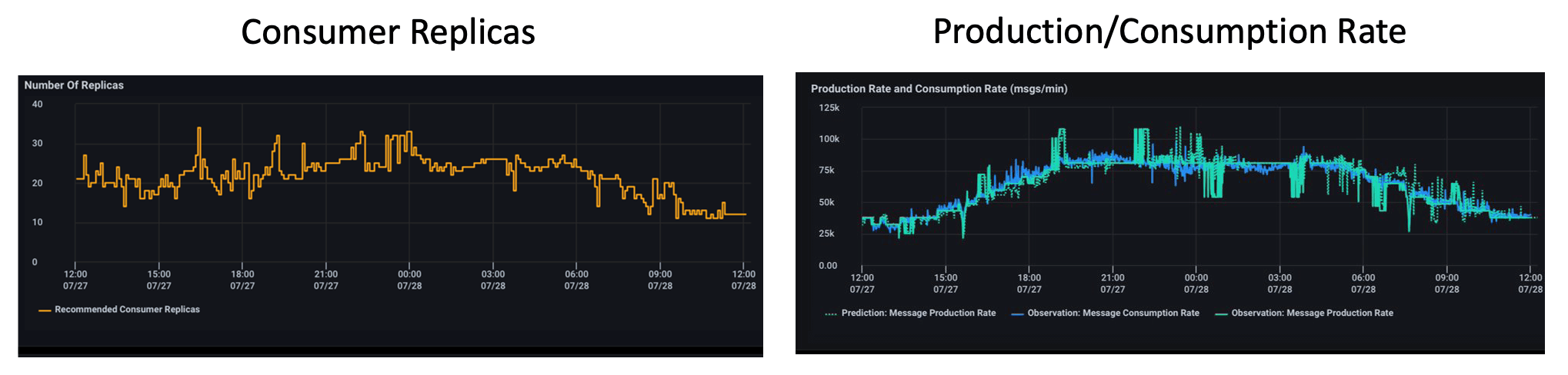
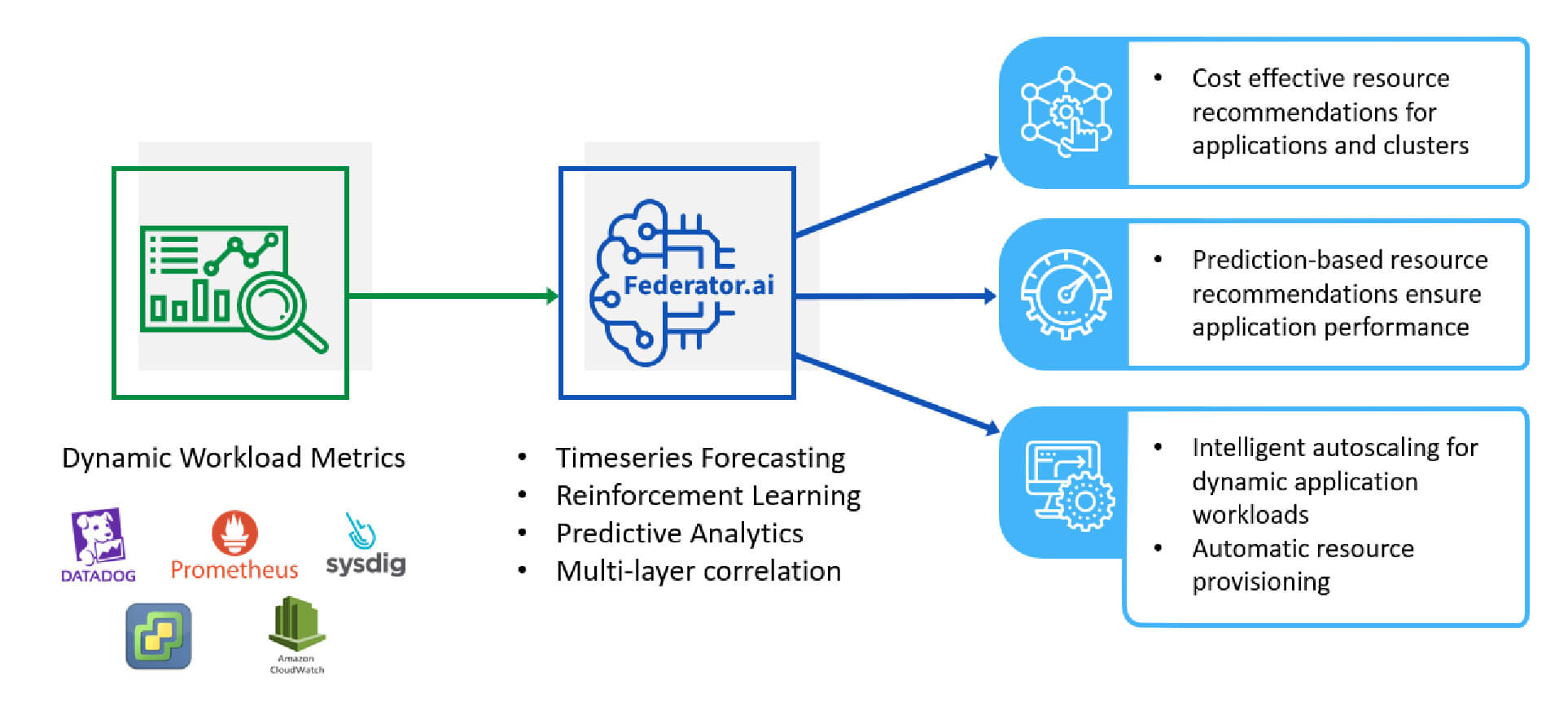
Federator.ai uses message production rate as a workload indicator, and makes predictions for this workload. It calculates the right number of consumer replicas based on predicted workload and target KPI metrics such as the desired latency to determine the capabilities of consumer pods. In contrast to the Kubernetes native HPA and KEDA, Federator.ai integrates the workload metrics, workload predictions, and application KPI in deciding the number of replicas. Users can utilize Federator.ai’s prediction-based intelligent autoscaling to achieve more cost-effective application deployments without compromising performance requirement.
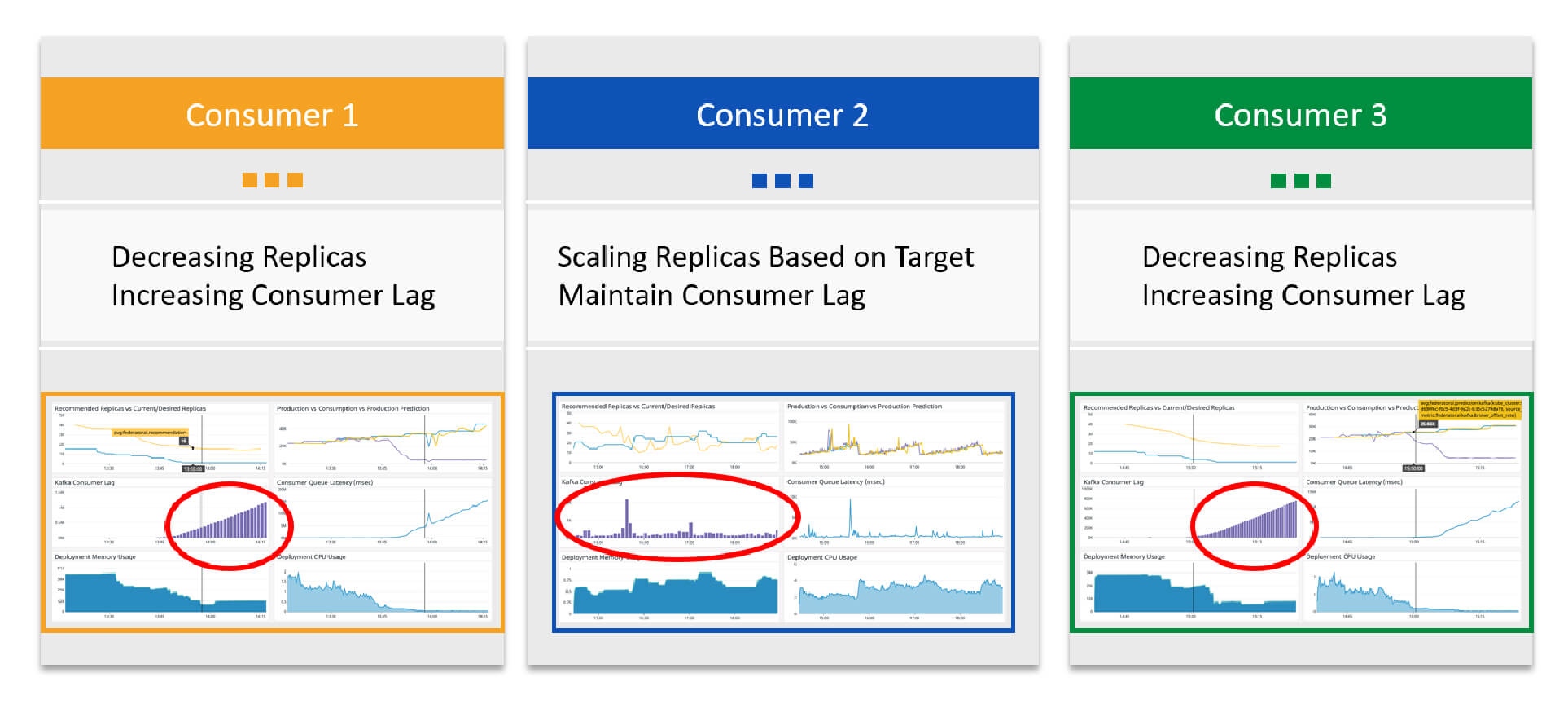
The Kubernetes native HPA on the other hand does not have predictive analytics capability nor ability to fuse various metrics intelligently. At best, it can recommend maximum number of replicas among the recommended replicas determined by various configured metrics. On the other hand, KEDA triggers autoscaling based on KPI such as lag offset to increase or reduce the number of replicas. In both cases, it is similar to watching in rear mirror since the lag offset is the difference between the production and consumption rates in the past.
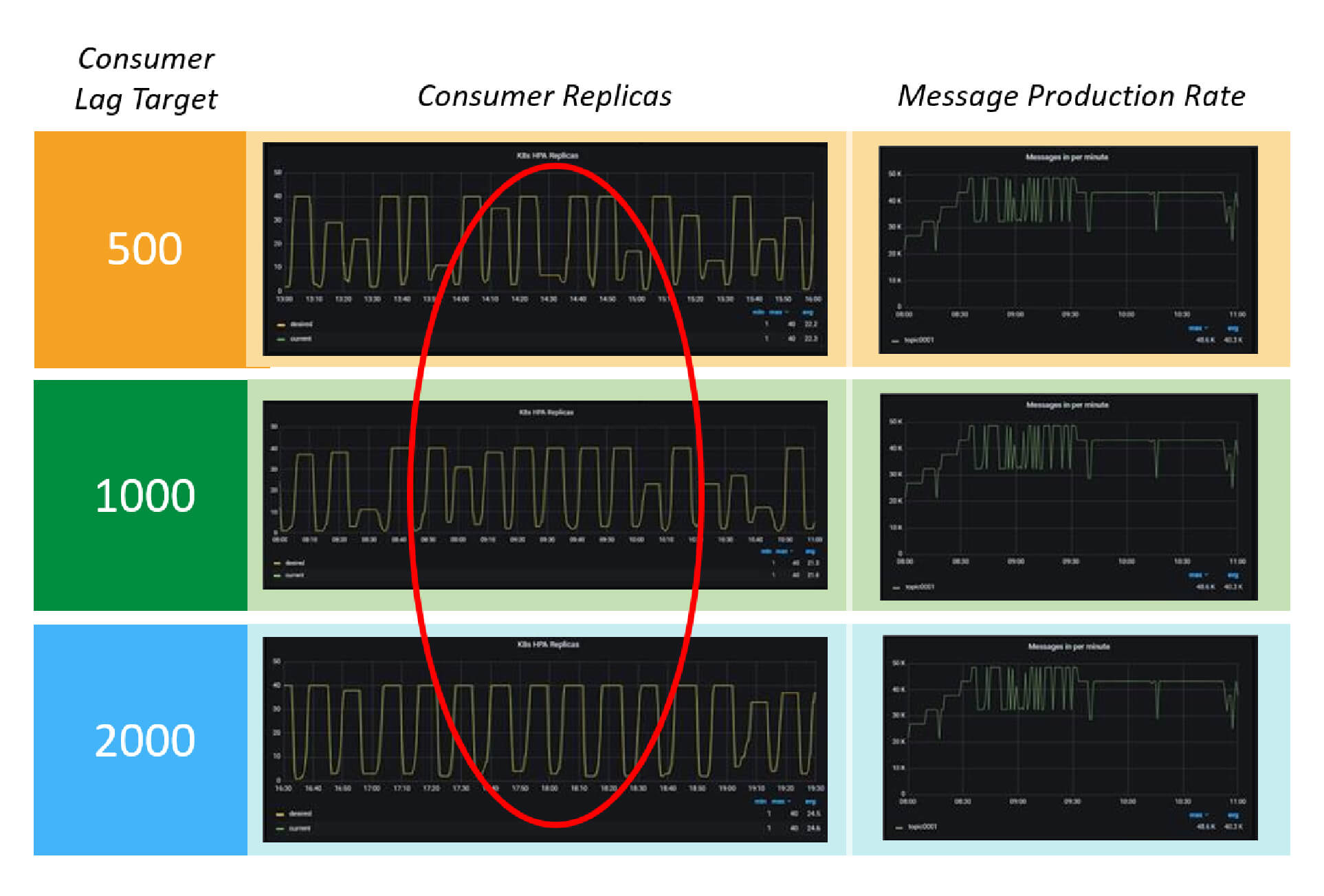
In contrast with the Kubernetes native HPA with consumer lag offset metrics results, Federator.ai’s consumer replicas and consumption rates can nicely track the production rate due to its predictive capability of the future workloads. The sharp oscillation of consumer replicas in the tests using native HPA with consumer lag offset can be explained as follows: if the target lag offset is set to too low (e.g., 1,000), any sudden large increase of consumer lag offset (e.g., 2,000) will lead to a large number of desired replicas (e.g., 2 times the original number of replicas) and likely over provisioned in respect to the workloads in our test results, which can happen when the production rates increase beyond the consumer pods processing capability. Once over provisioned, a similar workload will produce very low lag offset (e.g., 100 or less), the number of desired replicas will become much less (e.g., 1/10 or less of the original number of replicas). It’s also clear that the target lag offsets cannot set to too high, which will render an unacceptable consumer lags. It’s possible to remedy this situation with the cool down and upscale delay of the HPA configurations. However, it remains difficult to determine what’s the best values to configure them without a real production environment.
Please select the software/ platform you would like a demo of: