
Every autoscaling system on the market today reacts — it waits for a spike, then scrambles to respond. ProphetStor’s patented Predictive Self-Driving Autoscaling flips this model: it plans the optimal resource provisioning sequence across all future intervals, weighing both operational and transition costs, and executes the plan automatically through Kubernetes, VMware, and cloud autoscaling — before the demand ever hits.
The Fundamental Flaw in Reactive Autoscaling
Reactive autoscaling is like driving by looking in the rearview mirror. By the time the system responds, the damage is done.
Scaling Lag
By the time a threshold is breached and a scaling action completes, the spike has already degraded performance. Users experience slowdowns that could have been prevented with 5 minutes of foresight.
Costly Scaling Churn
Following demand predictions literally means scaling up and down repeatedly. Every scaling action carries cost — hardware stress, power consumption, rebalancing overhead. These hidden costs accumulate invisibly.
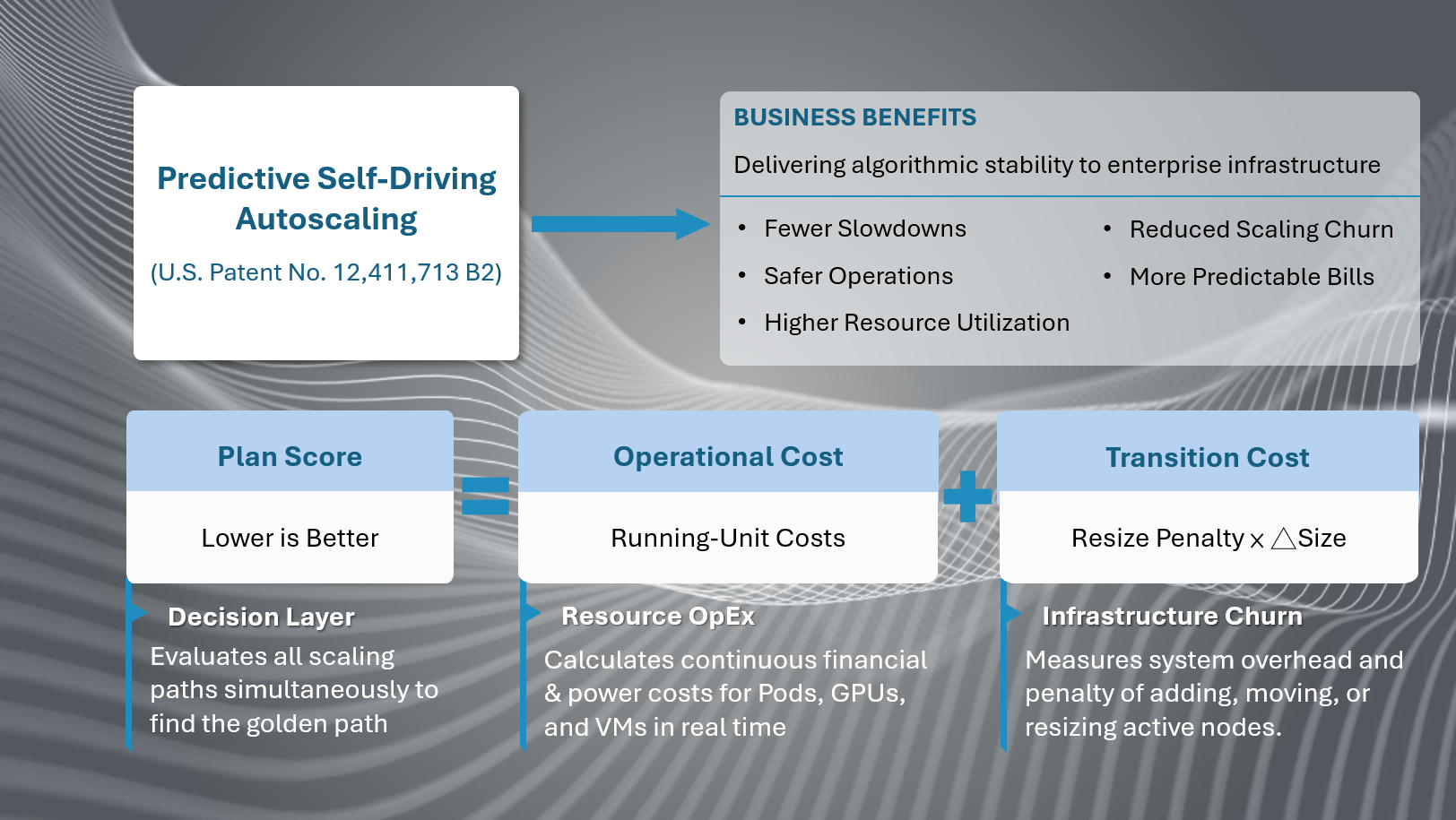
No Path Awareness
Existing tools optimize one moment at a time. A decision at the upcoming interval (T+1) data-index-in-node=”38″>T+1) affects total cost at the next future interval (T+2) through T+N — but no system accounts for this until the bill arrives at month-end.
What It Is
Predictive Self-Driving Autoscaling is ProphetStor’s patented method for planning the complete resource provisioning sequence across all future time intervals — finding the path that minimizes total operating cost while always meeting predicted demand — and executing it automatically.
The algorithm takes a demand forecast as input, evaluates all viable resource levels across N future intervals, and selects the sequence with the lowest accumulated cost (combining deployment, power, and transition costs). The result is a stable, efficient provisioning schedule executed through Kubernetes HPA/VPA, VMware vSphere, or cloud autoscaling APIs — with no manual intervention.
Conventional Prediction-based Autoscaling
Kubernetes assigns GPU resources at Pod creation. It allocates resources statically based on peak estimates, leaving GPUs heavily underutilized during lower-demand phases. When application phases change, GPUs sit idle, yet reactive adjustments risk triggering severe Out-Of-Memory (OOM) errors or heavy scheduling overhead.
Result: constant churn, hidden OpEx, performance gaps at critical moments.
ProphetStor Predictive Self-Driving Autoscaling
The system evaluates all provisioning paths simultaneously across future intervals. For example, holding 5 units from T+3 to T+5 costs less than dropping to 2 and spiking to 9 — even if 5 slightly exceeds demand at T+4. The algorithm automatically selects this optimal path.
Result: stable provisioning, predictable costs, zero reactive scramble.
Path-Planning Cost Model: The Cost-Optimization Formula for Predictive Self-Driving Autoscaling | ProphetStor
How It Works
A four-step process that runs automatically at each planning cycle.
STEP 01 · INPUT
Receive the demand forecast
A demand prediction covering N future time intervals is provided — specifying the number of resource units (CPU, memory, I/O) expected at each point. This can come from ProphetStor's multi-layer correlation engine or any external forecasting system.
STEP 02 · INITIALIZE
Calculate initial possible operation costs
At the starting point (T0), the system calculates the cost of each possible resource level for the next interval. The cost model includes: deployment cost (the more resources, the higher the base cost), rebalancing cost (the cost of changing from the current level), and an efficiency factor that rewards stable configurations.
STEP 03 · ITERATE
Propagate costs forward across all intervals
For each subsequent time interval (T+1 through T+N), the system repeats: find the smallest and second-smallest accumulated costs, determine which resource level produced them, and carry that forward. When two resource levels produce near-identical costs, both paths are explored in parallel before a winner is confirmed — similar to a decision tree pruning itself as new information arrives. This dramatically reduces computation compared to exhaustive search.
STEP 04 · EXECUTE
Provision resources on the optimal path
The result is a complete provisioning schedule — the exact number of units to deploy at each time interval — that delivers the lowest accumulated operating cost while always meeting or exceeding predicted demand. This schedule is applied automatically to the infrastructure.
U.S. Patent: Predictive Self-Driving Autoscaling
ProphetStor was granted a U.S. patent for the method of optimizing resource allocation based on prediction with reinforcement learning. The patent covers demand forecast integration, possible operation cost (POC) calculation with dynamic programming, selective path pruning, and automated execution — across GPU, CPU, memory, I/O throughput, response time, requests per second, and latency. Integrates natively with Kubernetes HPA/VPA, VMware vSphere, and major cloud autoscaling services.
Frequently Asked Questions
What is the core technical mechanism behind ProphetStor's predictive self-driving autoscaling?
The core mechanism is a forward-looking path planner that evaluates multiple possible resource allocation sequences and selects the one with the lowest total cost across N future time intervals. The algorithm identifies the sequence of allocation decisions including both the operational cost of each resource level and the transition cost (overhead) of moving between states. This process repeats continuously, so the system is always acting on a fresh plan that accounts for the most recent forecast. The result is a scaling behavior that anticipates load changes rather than chasing them — eliminating the lag-induced overprovisioning and underperformance that define reactive autoscaling.
What is scaling "path-planning" and why does it matter for AI workloads?
- High Interruption Costs: GPU training and inference tasks are highly sensitive to cold starts, pod evictions, and CUDA context initialization.
- Prevents Churn: A greedy autoscaler often triggers “scaling oscillation”—scaling down prematurely only to spike up minutes later, causing massive latency and compute waste.
- Holistic View: ProphetStor’s path planner sees both the surge and the stabilization, scheduling a single, optimized allocation change to absorb both smoothly.
How does predictive self-driving autoscaling reduce infrastructure costs without sacrificing performance?
ProphetStor cuts OpEx on two fronts simultaneously without breaching SLAs:
- Eliminating ‘Safety’ Buffers: Reactive systems require expensive “headroom buffers” (idle capacity) to absorb spikes during the scaling lag. ProphetStor scales before demand arrives, allowing you to run a much leaner, highly utilized infrastructure safely.
- Minimizing Transition Overhead: Every scale event incurs hidden costs: container warm-up times, rebalancing overhead, and network reconfiguration. By optimizing the entire path, the system reduces unnecessary scaling events.
Organizations achieve a rare win-win: higher GPU/CPU utilization (less idle waste) and greater system stability (fewer disruptive scaling events).
What workload types benefit most from predictive self-driving autoscaling?
This technology delivers the highest ROI for workloads characterized by predictable patterns and high transition penalties. When combined with our patented Spatial-Temporal GPU Optimization technology (U.S. Patent No. 12,596,580 B2), it provides unmatched efficiency for:
- AI/ML Infrastructure: LLM fine-tuning pipelines, batch inference, and large-scale training jobs that follow scheduled queues but suffer heavy cold-start latencies.
- Latency-Sensitive Production APIs: Customer-facing LLM inference engines, real-time recommendation systems, and scoring APIs where even a 5-minute scaling lag triggers catastrophic SLA breaches.
- High-Density Kubernetes Clusters: Complex multi-tenant microservices where reactive scaling churn creates severe scheduling bottlenecks.
How does this technology integrate with Kubernetes, VMware, and cloud environments?
ProphetStor operates as a non-disruptive, additive intelligence layer above your existing schedulers via native APIs:
- Kubernetes: Injects predictive intelligence directly into Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) configurations without modifying existing operators.
- VMware vSphere: Calculates optimal VM-level configurations per interval and orchestrates changes seamlessly via the vSphere API.
- Public/Hybrid Cloud: Integrates natively with AWS Auto Scaling Groups, Azure VM Scale Sets, and Google Cloud MIGs.
For Hybrid Cloud Bursting, the system cross-references resource costs with our Spatial-Temporal GPU Optimization framework. It treats local infrastructure and cloud burst capacity as a single optimization matrix, automatically choosing the lowest-cost path (local scale-up vs. cloud burst) based on real-time pricing and transition penalties.
How does predictive autoscaling coordinate with liquid cooling to support high-density GPU data centers?
There is a fundamental physics mismatch in modern AI Factories: GPU workloads spike in seconds, but liquid cooling systems (CDUs, pumps, fluid dynamics) take minutes to adapt. Reactive scaling causes immediate thermal hotspots, leading to GPU thermal throttling and energy-wasting emergency cooling responses.
ProphetStor bridges this gap by bridging our predictive autoscaling with our patented Multi-Layer Correlation technology (U.S. Patent No. 11,579,933 B2).
- By cross-correlating IT application metrics with OT facility data, the autoscaler shares its upcoming workload forecasts directly with Federator.ai Smart Liquid Cooling (SLC).
- Because the cooling infrastructure receives advance thermal notifications before the GPU workload shifts, it adjusts coolant flow and pump speeds proactively.
This multi-patent synchronization keeps chip temperatures stable, eliminates thermally induced throttling losses, and unlocks up to 30% energy savings while maximizing compute performance.
Is predictive self-driving autoscaling covered by a U.S. patent?
Yes. This breakthrough technology is protected under U.S. Patent No. 12,411,713 B2. The patent explicitly covers our forward-looking scaling method, including workload forecasting, the multi-interval cost-minimizing path algorithm, and automated execution across K8s, VMs, and cloud ecosystems.
This is the final pillar of ProphetStor’s AI Factory Patent Trilogy:
- U.S. Patent No. 11,579,933 B2 (Multi-Layer Correlation for full-stack infrastructure intelligence)
- U.S. Patent No. 12,596,580 B2 (Spatial-Temporal GPU Optimization for compute efficiency)
- U.S. Patent No. 12,411,713 B2 (Predictive Self-Driving Autoscaling for cost efficiency)
Together, they form the industry’s only patented, closed-loop autonomous orchestration suite for next-generation AI infrastructure.