
Most organizations waste more than 60% of their GPU investment — not because of bad hardware, but because they can’t predict and pack workloads efficiently across both space and time. ProphetStor’s world-first patented GPU optimization uses application behavior insights to maximize every dollar of accelerator spend — simultaneously optimizing which GPUs to use and when to run what.
The GPU Utilization Problem
Industry average GPU utilization (AI data centers)
Most of your GPU investment sits idle
With ProphetStor TS-DPBP optimization
Every GPU doing meaningful work
Why Kubernetes Alone Isn’t Enough for GPUs
Kubernetes was designed for CPU workloads. AI/ML training is a fundamentally different challenge.
Static Allocation
Kubernetes assigns GPU resources at pod creation. It allocates resources statically based on peak estimates. When application phases change, GPUs sit idle, yet reactive adjustments risk triggering Out-Of-Memory (OOM) errors or heavy scheduling overhead.
No Cross-Node Intelligence
Without visibility into the full cluster, GPUs sit idle on one node while another is starved. Fragmentation grows silently — a $1M cluster behaves like a $400K one.
Single-Layer View
Prior tools understood either GPU supply or application demand — never both together. Without correlating these layers, accurate placement and timing decisions are impossible.
What It Is
Spatial & Temporal GPU Optimization is ProphetStor’s patented approach, the TS-DPBP algorithm, to intelligent GPU resource management. It combines two dimensions of optimization simultaneously.
TS-DPBP (Time Series Dynamic Programming Bin Packing) predicts GPU demand using application workload forecasting, then plans both where workloads run and when capacity scales — treating the two as a single optimization problem rather than separate concerns.
Spatial — where workloads run
Decides how GPU workloads are placed across nodes, MIG partitions, and clusters using dynamic bin-packing. Spatial slicing divides each GPU into isolated instances — each with its own high-bandwidth memory, cache, and compute cores — so multiple workloads share hardware without conflict or cross-contamination.
Temporal — when capacity scales
Uses time-series forecasting to predict GPU demand across upcoming intervals before it arrives. Time slicing allows GPU partitions to be shared among workloads at different time slots. The system plans scaling across the full horizon so capacity is never left idle between jobs, and never scrambled for mid-training.
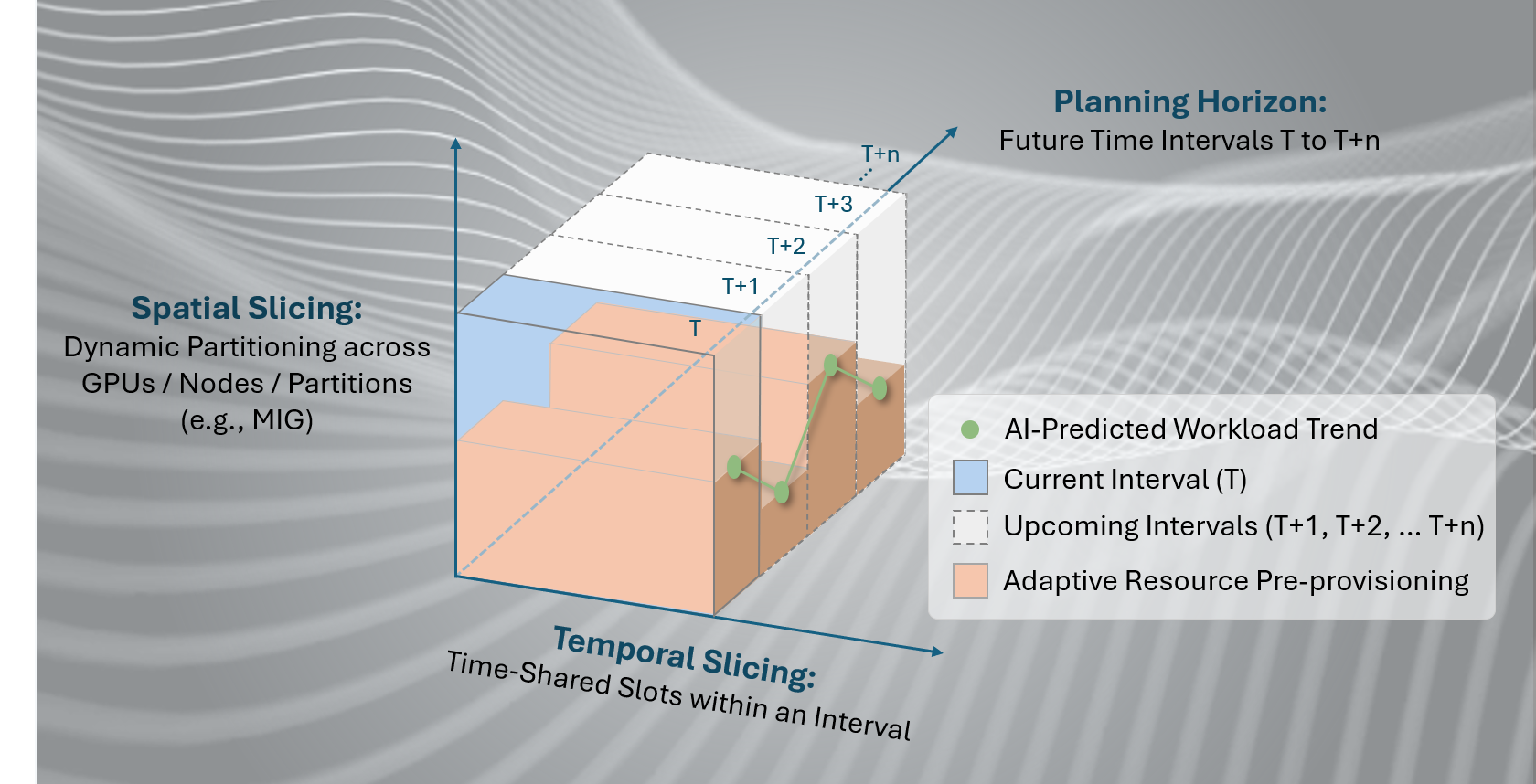
The Spatial-Temporal Architecture for Predictive GPU Resource Allocation | ProphetStor
How It Works
Three coordinated steps, running continuously — no manual tuning required.
STEP 01 · PREDICT
Cascade Causal Analysis
Continuously collects workload signals across the full stack—spanning application demand, sub-application behavior, and GPU resource usage. A time-series model then forecasts demand at T+1, utilizing our patented multi-layer correlation analysis to identify which GPU resources are most highly correlated with incoming workload changes.
STEP 02 · PLACE
Dynamic Bin Packing
A dynamic-programming planner evaluates all placement and scaling paths across the planning horizon. It minimizes total cost combining utilization efficiency, SLA penalties, and transition costs — moves only happen when they clearly pay off. Integrates with NVIDIA MIG, MPS, and CUDA.
STEP 03 · EXECUTE
Dynamic Allocation
Dynamically allocates and deallocates GPU resources via Kubernetes — pooling available GPUs across clusters, enabling auto-discovery of new hardware, and continuously adjusting allocations. Works with NVIDIA DGX Cloud, on-premises GPU clusters, and hybrid environments.
Standard Kubernetes GPU Scheduling vs. ProphetStor TS-DPBP
Standard Kubernetes GPU Scheduling
Reactive — allocates at pod creation, can’t adapt mid-training
Single-layer — sees GPU supply, not application demand
No cross-node placement intelligence — fragmentation grows
No GPU partitioning or time slicing awareness
Industry average: under 40% utilization
ProphetStor TS-DPBP (world's first patent)
✓
Predictive — anticipates demand before it arrives via time-series
✓
Full-stack — correlates app workload → sub-app → GPU resource
✓
Dynamic bin packing across nodes minimizes fragmentation
✓
Spatial + time slicing with MIG, MPS, and CUDA support
✓
Near-100% utilization — 50% less training time
U.S. Patent: Spatial & Temporal GPU Optimization
ProphetStor was granted the world’s first patent for Spatial and Temporal Optimization of GPU Utilization. The technology covers predictive GPU resource scheduling, dynamic allocation and deallocation, spatial and time slicing, cascade causal analysis, and full-stack multi-layer correlation — representing a comprehensive IP foundation for next-generation AI infrastructure.
Frequently Asked Questions
What is ProphetStor’s patented Spatial-Temporal GPU Optimization technology?
Spatial-Temporal GPU Optimization is ProphetStor’s patented method for maximizing GPU utilization in modern AI data centers by optimizing workload placement across two dimensions simultaneously. The spatial dimension governs where workloads run — which nodes, which GPU partitions, and how workloads are packed across the cluster to minimize idle capacity. The temporal dimension governs when capacity is adjusted — using time-series forecasting to predict what each workload will demand at the next scheduling interval, so resources are in place before demand arrives rather than after. Together, these two dimensions produce GPU utilization rates approaching 90%, compared to the industry average of under 40%. The technology is covered by U.S. Patent US12596580B2.
What is the TS-DPBP algorithm?
TS-DPBP — Time-Series Dynamic Programming Bin Packing — is the core algorithm behind ProphetStor’s patented GPU optimization. It works in two stages. First, it uses time-series forecasting to predict what GPU resources each workload will need at the next time interval, before scheduling decisions are made. Second, it uses dynamic programming to calculate the globally optimal workload placement across all available nodes and GPU partitions — minimizing a cost function that accounts simultaneously for utilization efficiency, SLA compliance risk, and transition cost (the overhead of moving a workload between nodes). Unlike static bin packing, which optimizes placement at a single point in time, TS-DPBP plans across a time horizon, choosing the path that minimizes total cost for GPU orchestration over multiple future intervals.
Why does standard Kubernetes GPU scheduling underperform?
Standard Kubernetes GPU scheduling assigns resources at pod creation time based on a workload’s declared resource request, then leaves that assignment fixed. It has no mechanism to forecast whether that workload’s demand will rise or fall, no awareness of GPU partition state (MIG slices, MPS contexts) across the cluster, and no cross-node intelligence to rebalance when utilization patterns shift. The result is structural waste: GPUs sit idle between jobs, over-provisioned requests block allocation for other workloads, and peak-demand spikes arrive faster than the scheduler can respond. Industry reports consistently show Kubernetes GPU clusters running at under 40% average utilization — a figure that reflects the scheduler’s inability to predict and plan, not a hardware limitation.
What GPU utilization can ProphetStor's TS-DPBP achieve?
In production AI factory environments, ProphetStor’s patented TS-DPBP algorithm achieves GPU utilization rates approaching 90% — more than double the industry average of under 40% found in standard Kubernetes deployments.
This unprecedented efficiency translates directly into massive operational and financial advantages for organizations running large-scale AI infrastructure:
- 50% Reduction in Training Time: By eliminating fragmentation and ensuring continuous workload packing, the time-to-market for complex LLM and generative AI models is cut in half.
- Zero OOM (Out-Of-Memory) Events: The predictive engine anticipates memory-intensive spikes before they happen, dynamically resizing partitions to guarantee workload resilience during heavy inference.
- Maximized ROI on Next-Gen Hardware: The technology smoothly scales its efficiency across multi-GPU nodes, NVIDIA MIG-partitioned architectures (including A100, H100, and H200), and multi-tenant AI clusters, turning idle silicon into active, meaningful compute.
What NVIDIA GPU technologies does Spatial-Temporal GPU Optimization support?
ProphetStor’s TS-DPBP algorithm is purpose-built to orchestrate and optimize across all three major NVIDIA GPU partitioning technologies:
- Multi-Instance GPU (MIG): TS-DPBP treats each isolated hardware slice as a dynamic schedulable unit, packing workloads perfectly to guarantee dedicated memory and compute bandwidth without fragmentation.
- Multi-Process Service (MPS): The system intelligently manages concurrent CUDA processes sharing a single GPU, maximizing hardware throughput while eliminating inter-process resource contention.
- Standard CUDA Time-Slicing: Traditional oversubscription workloads are also fully supported and balanced.
The solution integrates natively with NVIDIA DGX Cloud, on-premises GPU clusters, and Kubernetes environments using standard NVIDIA device plugins, making it fully compatible with both hyperscale AI factory deployments and enterprise private data centers.
How does Spatial-Temporal GPU Optimization differ from standard GPU bin packing?
Standard GPU bin packing solves a static, one-dimensional problem: it looks at a snapshot of workloads and available GPU capacity right now and finds a placement to minimize waste at this exact moment. It is reactive, single-point, and completely blind to how demand will evolve or the heavy migration overhead incurred when moving workloads later.
ProphetStor’s Spatial-Temporal GPU Optimization solves a continuous, two-dimensional optimization problem across space and time:
- The Spatial Dimension: It evaluates all available nodes, MIG slices, and MPS contexts simultaneously.
- The Temporal Dimension: It projects how each workload’s GPU demand will change over a future planning horizon.
By planning ahead, our TS-DPBP algorithm can deliberately leave headroom in specific GPU partitions when it forecasts a high-demand workload is about to arrive. This predictive placement avoids the costly, performance-degrading rebalancing loops that static bin packing inevitably triggers when AI workloads spike.
Is Spatial-Temporal GPU Optimization patented?
Yes. U.S. Patent US12596580B2 covers the method and system for spatial and temporal GPU optimization, including the integration of time-series demand forecasting with dynamic programming bin packing for workload placement. The patent’s claims cover the full pipeline: collecting workload and resource metrics across nodes, calculating correlation values between application behavior and GPU consumption, applying time-series models to forecast future demand intervals, using dynamic programming to evaluate placement paths with pruning for computational efficiency, and executing the selected allocation plan automatically. It is the world’s first patent specifically covering spatial and temporal optimization of GPU utilization. The patent can be viewed at Google Patents.