
Introduction
A Kafka Stream Application reads data from a topic, performs calculations and transformations, and then writes the result back to another topic. To read from a topic, it creates a consumer. Kafka has become a standard tool for managing a high-load streaming system. However, it lacks built-in mechanisms for dynamic cluster capacity planning and scaling strategies. Scaling the application involves running more consumers. Typically, to optimize the consumer processing rates, users assign the same number of consumers as there are partitions for related topics. However, this ‘over-provisioning’ approach can lead to unnecessary resource waste. To address this, some efforts have been made to use Kubernetes Horizontal Pod Autoscaler (HPA)[1] to manage consumer groups in a Kafka cluster[2] [3], with the hope that the autoscaler can dynamically allocate the right amount of resources at the right time, improving resource utilization. However, there are some drawbacks to using Kubernetes HPA:
- Limitations of Kubernetes HPA: Kubernetes HPA combines recommendations (calculating desired replicas) with executions (adjusting the number of replicas) via the HPA controller. As operator-based applications become more prevalent in Kubernetes clusters, Kubernetes HPA is less suitable for auto-scaling these applications. In some cases, users may prefer to receive only scaling recommendations and handle executions separately through custom methods.
- Challenges with Metrics: If the metrics used to calculate the desired number of replicas are not chosen carefully, performance can suffer. Users need to carefully select appropriate metrics, often through trial and error, to avoid negative impacts on performance.
In this article, we demonstrate that the native Kubernetes HPA algorithm (K8sHPA mechanism) provides modest savings but results in significant latency. Federator.ai from ProphetStor leverages machine learning to predict and analyze Kafka workloads, recommending the optimal number of consumers based on a balance of performance and cost. This approach achieves better performance (reduced latency) and uses fewer resources (reduced Kafka consumers), all without modifying the K8sHPA mechanism or Kafka code. As a result, users can flexibly apply Federator.ai’s recommendations and customize their executions as needed.
Current Issues

In this formula, the desired number of replicas is calculated by comparing the current metric value to the desired metric value (e.g., targetAverageValue or targetAverageUtilization). For example, in Kafka, the targetAverageValue can be 1,000 lags in a topic for a consumer group. However, setting this value based solely on user experience is insufficient for large-scale Kafka deployments, such as Netflix’s Kafka cluster, which manages 4,000 brokers and processes 700 billion events daily [4]. Manual configuration in such environments is impractical, highlighting the need for an AI-based management tool to better manage scaling and resource allocation.
Typically, topics accumulate lags when producers send messages, and consumers gradually reduce these lags. Kubernetes HPA periodically checks the lag value and adjusts the number of consumers based on the observed currentMetricValue relating to the desiredMetricValue, as shown in the formula. However, the scaling decisions are based solely on the current metric value, without accounting for the impact of adding or removing consumers. When the number of consumers is adjusted, Kafka undergoes a rebalancing process where partitions are reassigned for consumers [5]. During this rebalancing, consumers temporarily stop processing messages. Furthermore, partition reassignment can cause two issues: (1) duplicate message processing if the new consumer’s committed offset is smaller than the last processed offset, or (2) message loss if the committed offset is larger than the last processed offset. These issues increase the time and resources required to handle the offsets, introducing what is known as an auto-scaling cost.
The Kubernetes HPA controller scales the number of consumers based solely on the current lag value, without accounting for the associated auto-scaling costs. As a result, it may add or remove consumers too aggressively, with new consumers becoming effective only after rebalancing is completed, which can take up to 30 seconds. This delay can lead to performance fluctuations, increasing queue lengths and negatively impacting Kafka’s performance.
How ProphetStor’s Federator.ai Helps
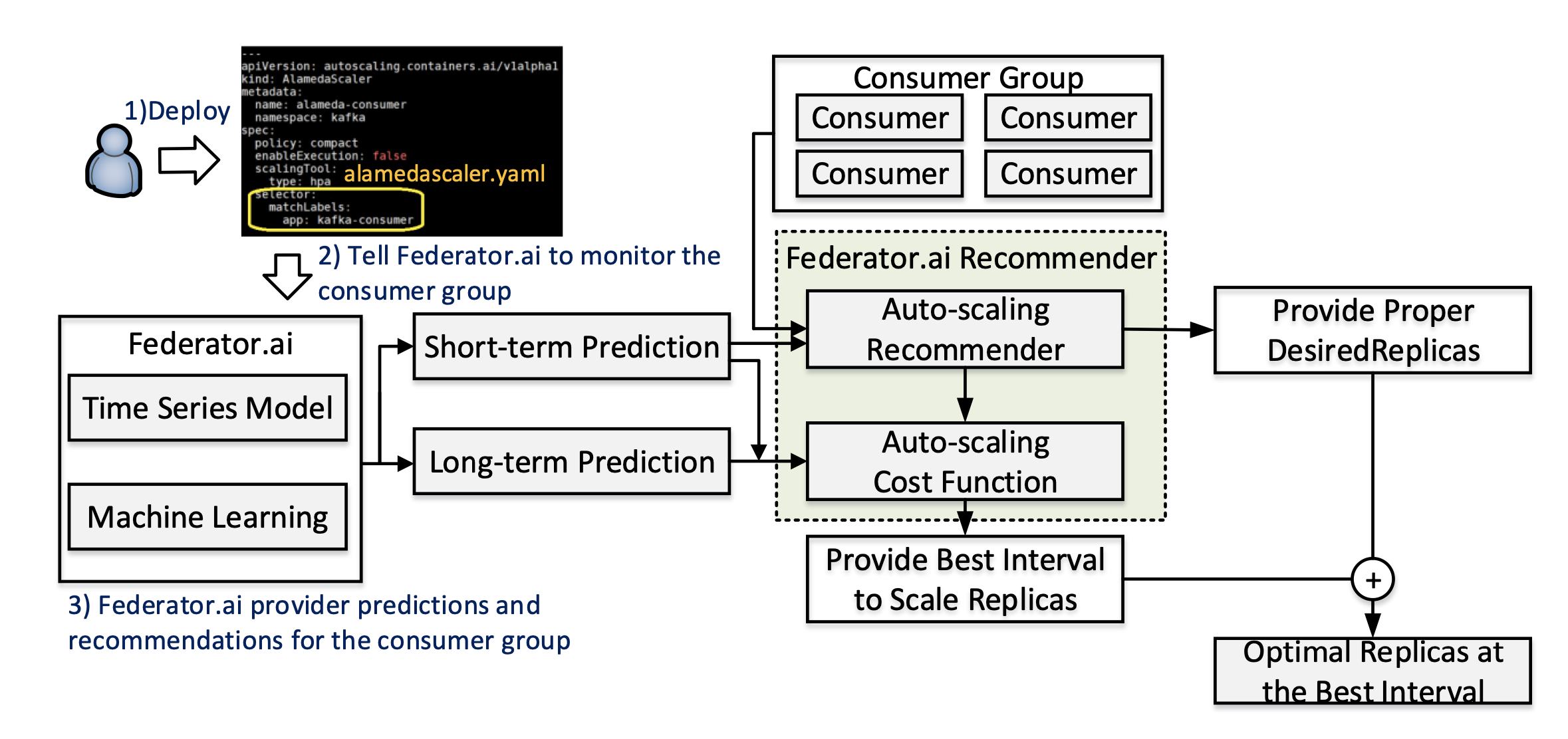
At ProphetStor, we aim to bring AI technology to IT Operations (AIOps) in Kubernetes, simplifying the task of running Kafka on Kubernetes. Federator.ai Recommender’s architecture for providing recommendations to support Kubernetes’s Autoscaler is shown in Figure 1. ProphetStor’s Federator.ai is an application-aware add-on to Kubernetes. When users deploy a custom resource definition (CRD) – alamedascaler.yaml – to label a consumer group as “Kafka- consumer,” Federator.ai starts to collect data about the consumer group and generates predictions. Using time series models and machine learning technology, it analyzes workload data to produce long-term and short-term forecasts. The Federator.ai Recommender comprises two components: the Auto-scaling Recommender and the Auto-scaling Cost Function. The Auto-scaling Cost Function uses long-term and short-term predictions to articulate auto-scaling costs, recommend the optimal time for auto-scaling, and minimize operation costs. The Auto-scaling Recommender adopts short-term predictions to estimate resource utilization and recommend the ideal number of replicas (desiredReplicas) for scaling.
Users can form Kafka consumer group using a deployment in a Kubernetes cluster via the Kafka consumer API [6] or Kafka client tools [7][8]. Each consumer in the group can connect to external services like MySQL or Elasticsearch through custom Kafka connectors [9][10]. Federator.ai Cost Function helps recommend the best auto-scaling intervals to reduce scaling overheads. Additionally, Federator.ai recommends the optimal number of consumers by balancing the benefits of HPA and cost functions, allowing system managers to focus on their core responsibilities while enjoying reduced costs and enhanced performance.
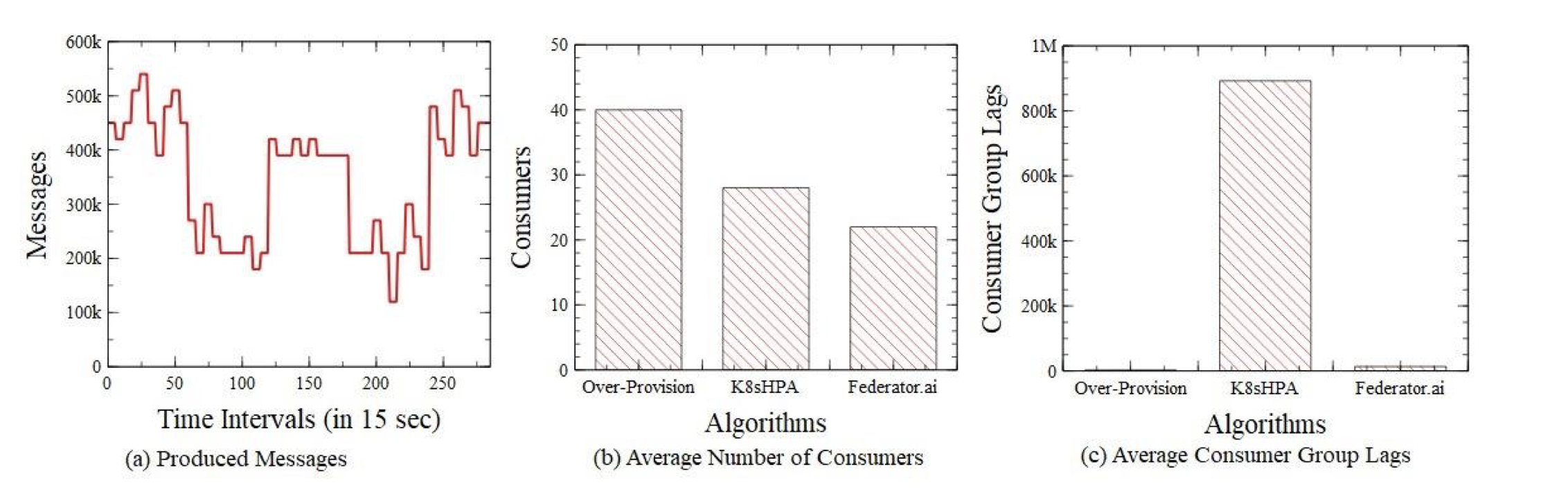
Figure 2(a) shows a real workload pattern from Alibaba [11]. Figures 2(b) and 2(c) present benchmark results for a Kafka cluster on Kubernetes. A producer sends messages to a topic with 40 partitions, as depicted in Figure 2(a). In the “Over-Provision” scenario, users allocate 40 consumers to access messages for the topic. In the “K8sHPA” scenario, consumers are dynamically assigned using Kubernetes HPA, with the targetAverageValue at 10,000 lags. In the “Federator.ai” scenario, the Federator.ai Recommender leverages AI-powered predictions, accounting for the cost function to recommend the optimal number of replicas at the best intervals. As shown in Figures 2(b) and 2(c), the K8sHPA mechanism results in nearly 900,000 lags per interval, with each message waiting for an average of 117 ms. In contrast, Federator.ai reduces lags to 14,000, with an average wait time of just 2 ms per message. Figure 2(b) highlights that Federator.ai reduces the average number of consumers (execution cost) by 45% compared to the Over-Provision scenario. This result shows that Federator.ai reduces average consumer group lags (latency) by 98.46% compared to the K8sHPA mechanism.
Summary
References
[1]. “Horizontal Pod Autoscaler,” Kubernetes. Available: https://kubernetes.io/docs/tasks/run- application/horizontal-pod-autoscale/
[2]. Jaroslaw Kijanowski, “Autoscaling Kafka Streams applications with Kubernetes,” SoftwareMill, Jul. 15, 2019. Available: https://blog.softwaremill.com/autoscaling-kafka-streams-applications-with-kubernetes-9aed2e37d3a0
[3]. Sunny Gupta, “Kubernetes HPA Autoscaling with Kafka metrics,” Medium. Dec. 27, 2018. Available: https://medium.com/google- cloud/kubernetes-hpa-autoscaling-with-kafka-metrics-88a671497f07
[4]. Allen Wang, “Kafka At Scale in the Cloud,” SlideShare, May. 10, 2016. Available: https://www.slideshare.net/slideshow/kafka-at-scale-in-the-cloud/61833011
[5]. N. Narkhede, G. Shapira, T. Palino, “Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale,” Amazon. Oct. 24, 2017. Available: https://www.amazon.com/_/dp/1491936169?smid=ATVPDKIKX0DER&_encoding=UTF8&tag=oreilly20-20
[6]. “Documentation,” Kafka. Available: https://kafka.apache.org/documentation/
[7]. “Apache Kafka Helm Chart,” GibHub. Available: https://github.com/helm/charts/tree/master/incubator/kafka
[8]. “Strimi, Run Apache Kafka on Kubernetes and OpenShift,” GitHub. Available: https://github.com/strimzi/strimzi-kafka-operator
[9]. S. Sebastian, “Setup Kafka with Debezium using Strimzi in Kubernetes,” Medium. May. 31, 2019. Available: https://medium.com/@sincysebastian/setup-kafka-with-debezium-using-strimzi-in-kubernetes-efd494642585
[10]. Arash, “Apache Kafka® on Kubernetes®,” Medium. Apr. 26, 2019. Available: https://blog.kubernauts.io/apache-kafka-on-kubernetes-4425e18daba5
[11]. “Alibaba Trace,” GitHub. Available: https://github.com/alibaba/clusterdata