Mike Waite, Senior Principal Product Marketing at Red Hat, interviewed ProphetStor CEO Eric Chen and EVP of Products Ming Sheu on OpenShift TV on December 16, 2020, to talk about ProphetStor’s vision and mission.
ProphetStor has been working on AI-enabled proactive management to address the complexity in Hybrid MultiCloud environments. Ming also showed a demo about the Federator.ai integration with Datadog Monitoring Services.
The following is a link to the recording and detailed presentation material illustrating how ProphetStor provides the solutions and how it brings customers’ values to optimize the cost and performance in Hybrid MultiCloud operations.
Please see the following for more about the interview.
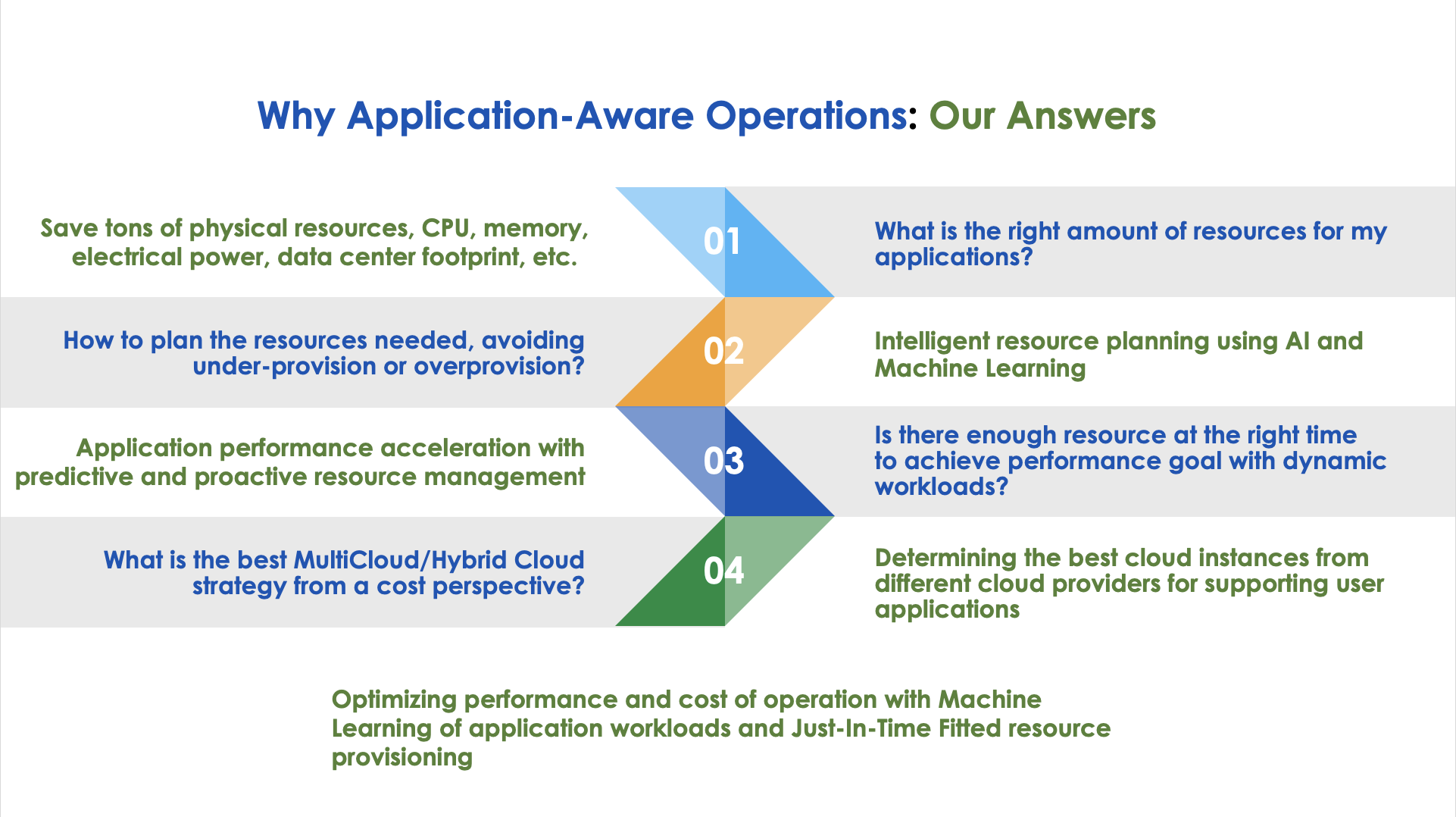
We are a group of industry veterans with expertise in IT management, Infrastructure and Cloud Operations, Data Sciences, and AI technologies. We share the vision that the purpose of the IT Infrastructures and Cloud Services is to ensure that the purposes of the applications can be served and that they need to be proactive and upfront to avoid afterthoughts. The complexity of the operation can be minimized, cost saved, and performance optimized if we can understand the workload behaviors and match the requirements with the right amount of resources at the right time.
Managing the existing IT infra and Cloud operations are all very passive tasks, requiring a lot of human ingenuity. The situation worsens when we bring in the containerized applications, the dev/ops operation, and the new MultiCloud paradigms. Besides, workloads are mostly dynamic. It is challenging to track, manage, and optimize, and it gotta need a huge change.
There is one interesting story I want to share with you:
Many years ago, when I was working in the previous company I helped co-founded, we sent a group of engineers to install a software-defined storage solution at a remote customer site. After two weeks of work, they finished the job, got compliments from that very demanding customer, and returned to the company in triumph. We were all pleased, engineers and managements alike, thinking that this is yet another success story that we can share with the rest of the world, and we are on our way to an even bigger thing.
One week later, I visited that SI partner that we worked together to handle this customer’s case, thinking that the CEO of that SI will greet me with a celebrating party. On the contrary, there was no red carpet and no dinner. The CEO of that SI told me, “Eric, it was a great project: the customer is happy, we made good money, and you have a good support/engineering team. However, I would like to terminate our reseller contract effective immediately.” I was shocked, to say the least!
“Why?” I asked, “I thought that we had a great case, and we are unto more successes in the future!”
“Well,” the CEO said, “I watched my team working with your engineers, and they are all exhausted to get into the details of the configuration. They needed to be very careful every step of the way, connecting the cables, getting the right sizing information, watching closely about the application behaviors, and a lot of times, they needed to guess the resources required to meet the SLAs. The storage management is only about space/capacity, rather than performance, and cannot solve the major issues I have seen in the operation.”
“The opportunity cost is too high working with your product.” he added, “There gotta be a better way, a more automatic and intelligent way.”
For me, that was a real mind-boggling conversation, and that changed everything.
Years later, after I left my previous company and I met with Dr. Sunny Siu, an MIT professor and a series entrepreneur. We started to talk about bringing the application-awareness first to storage management and then to the IT and Cloud, and it clicked so well. He is the brain of what we do. At the time of 2012, AI was still in its hibernation. We decided that we need to have a company to bring AI/Machine Learning technologies for managing applications and resources. That went very well, and Sunny became an investor and the president of the company. We believe that if we walk back to the SI that I dealt with many years ago, I would be greeted with a red carpet and champagne this time with our solution. And that’s what we do: automate and optimize Kubernetes operations with AI/Machine Learning.
As you will see, we are focusing on Day 2 Operation of the Kubernetes/OpenShift platform because our eyes are on operation automation and efficiency. We believe these will be the major issues that need to be addressed for broader acceptance of the platform.
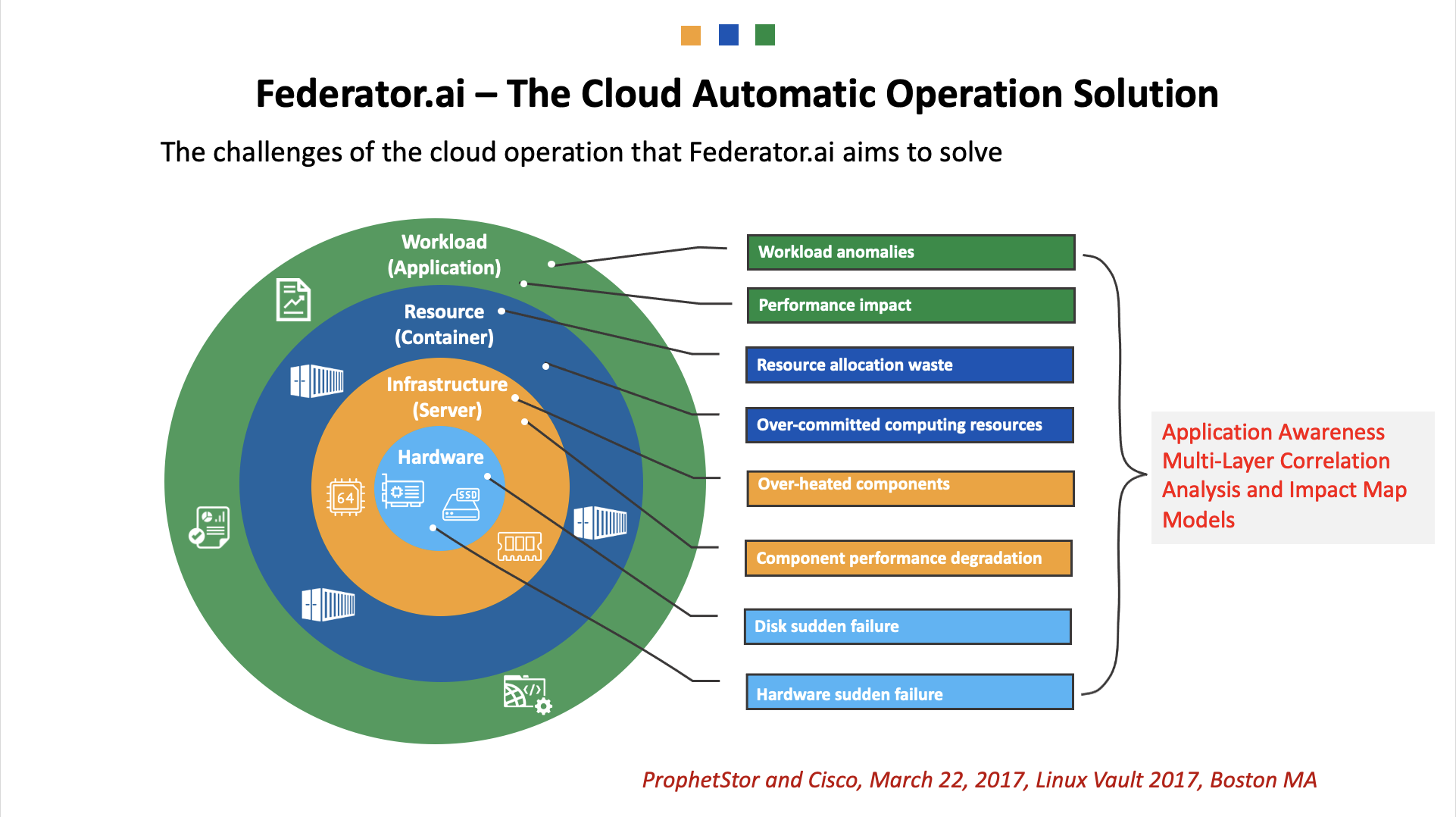
Since we are working on a product that addresses the efficiency and cost issues, the user personas are operation managers, CIOs, CFOs, and CEOs. Kubernetes is agile, high-performance, and flexible. However, it is also very complicated to manage. Still, the complexity did not outweigh the benefits of the platform and thus, the popularity caught up swiftly. Therefore, simplicity of deployment is essential, and it is the center of focus of the products of the first phase of adoption. For me, the most significant benefit of Kubernetes and the container paradigm is the openness and transparency it presents to the management. We now are able to observe the details of the operation, from application to the container levels, and then down to infrastructure, cloud operation, hardware components, and even to the CPU cores and DMA functions.
On the other hand, the self-imposed restriction on the horizontal division and layers of IT systems, such as databases (such as MongoDB, Postgress), and virtualization platforms, such as Kubernetes, operation systems, such as RHEL, and hardware, such as Intel or AMD CPUs, they all excel in providing the best breed of products IN THAT LAYER. As a result, anything beyond that specific layer, they chose not to see or optimize. That is, they tend to be heuristic and general-purpose. In the Kubernetes/OpenShift platform, the self-imposed restriction is a true waste of innovation. We ought to leverage the transparency of the WHOLE system, from the application, to system, and all the way to resources. A great orchestrator can then be introduced to match the requirements from the application to the resource provisioning. And that is why we wanted to have the Federator.ai.
The Market Landscape of Kubernets/MultiCloud/OpenShift
In recent market developments, you can see the vendors offering monitoring services or solutions became very popular. These include Datadog, Dynatrace, Sysdig, Instana, SignalFX, etc. They help resolve the “visibility issues” in Kubernetes and Cloud platforms. The solutions for container monitoring was not se5mature or not there just a few years back. And when you move to the cloud, you lost the visibility of the application and systems running on that cloud unless you subscribe to the monitoring services. So we think the market of monitoring will still be in high demand in the near future. Proof of that is that IBM just acquired Instana a few weeks back.
The next issue to be addressed is security. We can see some active vendors, such as Sysdig, in the market in that category.
The next big trend, we believe, is the phase 2 adoption involving Day 2 Operation. After deploying the workload to the cloud, the administrator will face the next issues of operational efficiency in performance and cost. A lot of managers had sticker shock when they received the cloud bills. I myself am a victim, and I can testify that. I think it is valid to say that without good planning and a proper understanding of the operation model of Cloud Computing and how it is charged, the performance of the application and cost of running a workload on the cloud might not be as good as expected. Also, MultiCloud brings along yet another dimension of complexity: selecting the best pricing plan to meet the SLA of the workload. Now you have more than one Cloud service providers you can go to. In addition to that, each data center of one service provider might offer very different pricing for the same instance.
As a result, we believe ProphetStor can contribute to the community by offering our AI-enabled, proactive management solution for automation, performance, and operation costs. These are all good for the Day 2 Operation, and I will use the slides to talk about that. A key differentiation from other solutions, before we start, is that our solution considers the full-stack of operation. Also, it is the right combination of Engineering and Science, so that the solution needs the right amount of computing power to justify the benefits it brings.
To simplify my presentation, I only use examples to showcase the issues we help resolve in the following presentation slides.
The proactive way of management in Kubernetes, OpenShift in particular, with the help of AI technology and how we can do the performance and cost optimization in MultiCloud
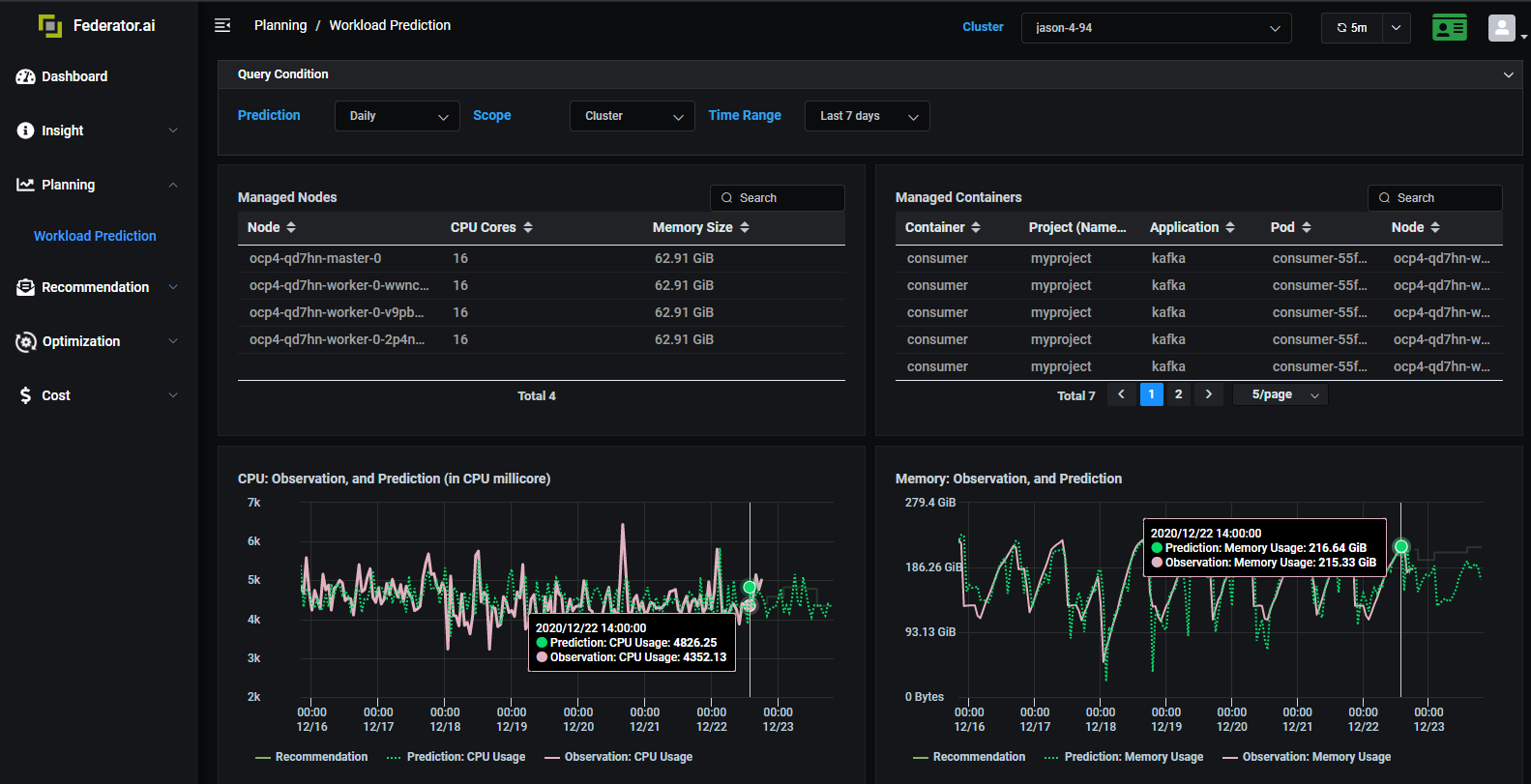
Knowing when the workload is going to change can assist us in good resource planning.
Federator.ai allows users to observe the workload predictions at different layers of applications/resources in a Kubernetes or an OpenShift cluster.
With different prediction granularities and prediction results for different resource layers, users can do better resource planning to optimize their performance and resource utilization.
Application-Aware Workload Prediction and Autoscaling
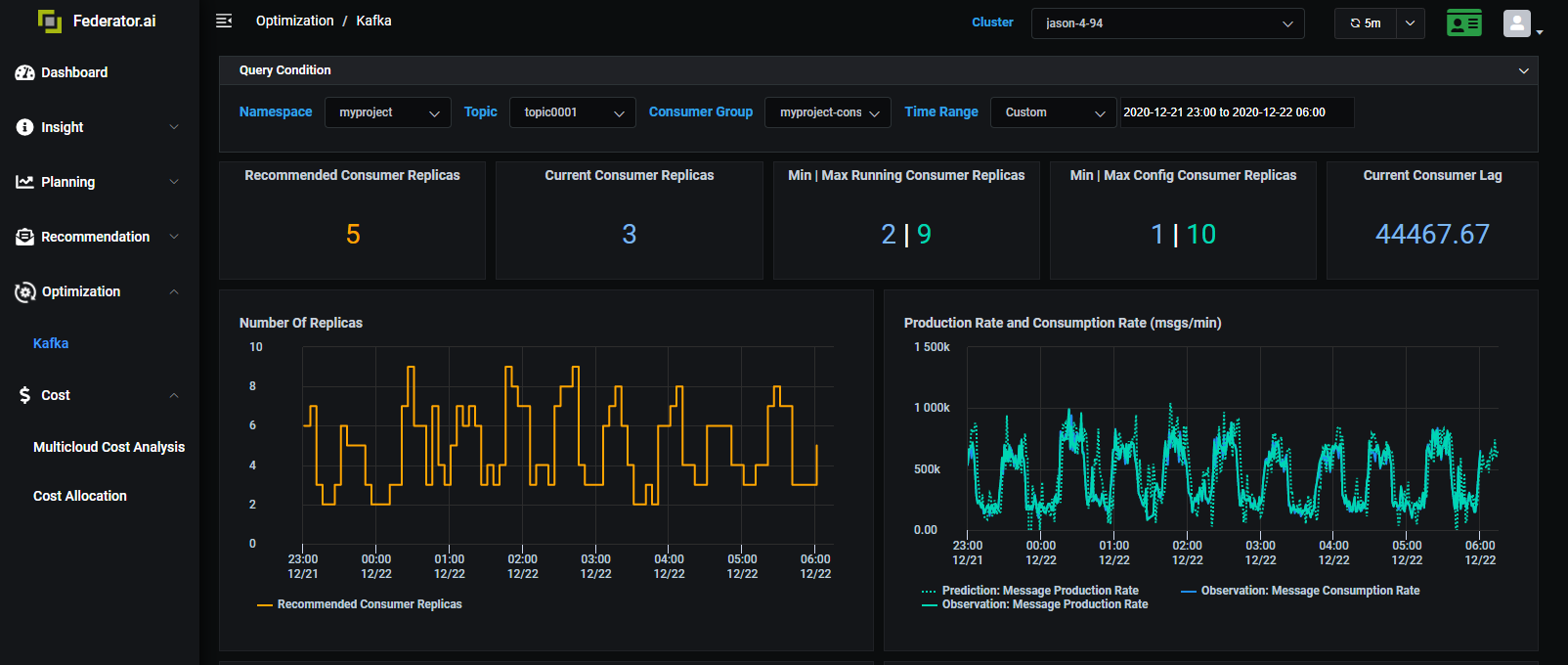
CPU or Memory usage, most of the time, is not a good indicator for the real workload. Take Kafka as an example; you have many Kafka producers sending messages to Kafka brokers at different rates at different times of the day. You want to make sure you have enough Kafka consumers to receive and process those messages in time without causing a lot of delays. CPU usage of Kafka consumers is not the best workload indicator. In this case, the production rate of messages from producers is the right workload metric. With Federator.ai’s ability to predict the appropriate workload, we can dynamically scale the Kafka consumer so that the right amount of consumer pods will be serving the Kafka messages at the right time.
This is an excellent example of providing action when one can predict the dynamic workload in nature.
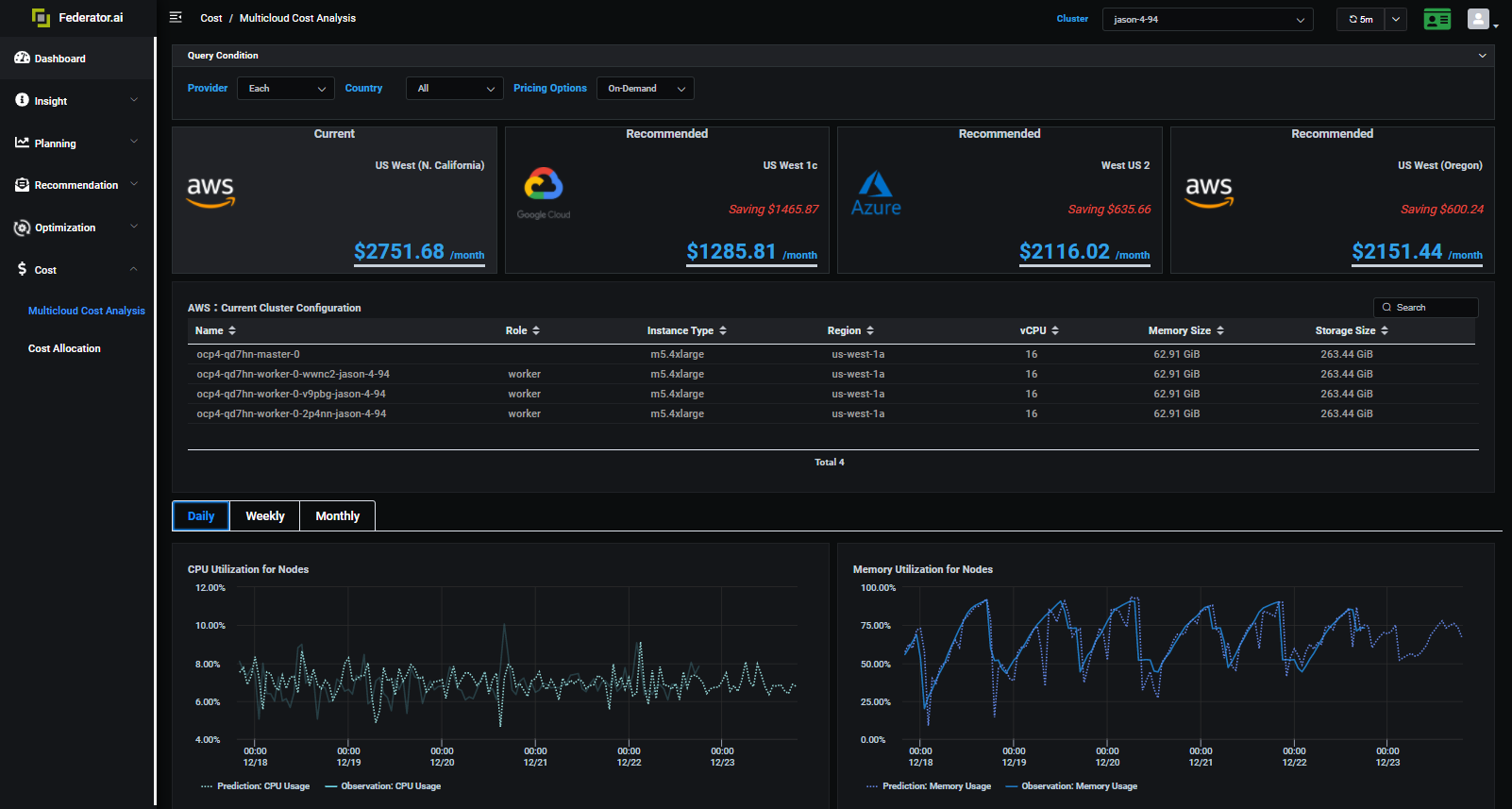
Multi-Cloud Cost Analysis
We can achieve more benefits when we fully understand the future workloads and use that in deciding appropriate resources. For example, you might be considering moving your current on-premise clusters to a public cloud service provider. Knowing your future workload will help you choose the right instances that are most cost-effective and, at the same time, handle the workload for the cluster.
Even if you are already a customer of AWS, you can still utilize Federator.ai’s analysis to give you a recommendation of what instance types in what regions would reduce your cost. Federator.ai provides you different ways of cost estimates based on on-demand, reserved, or even SPOT instances.
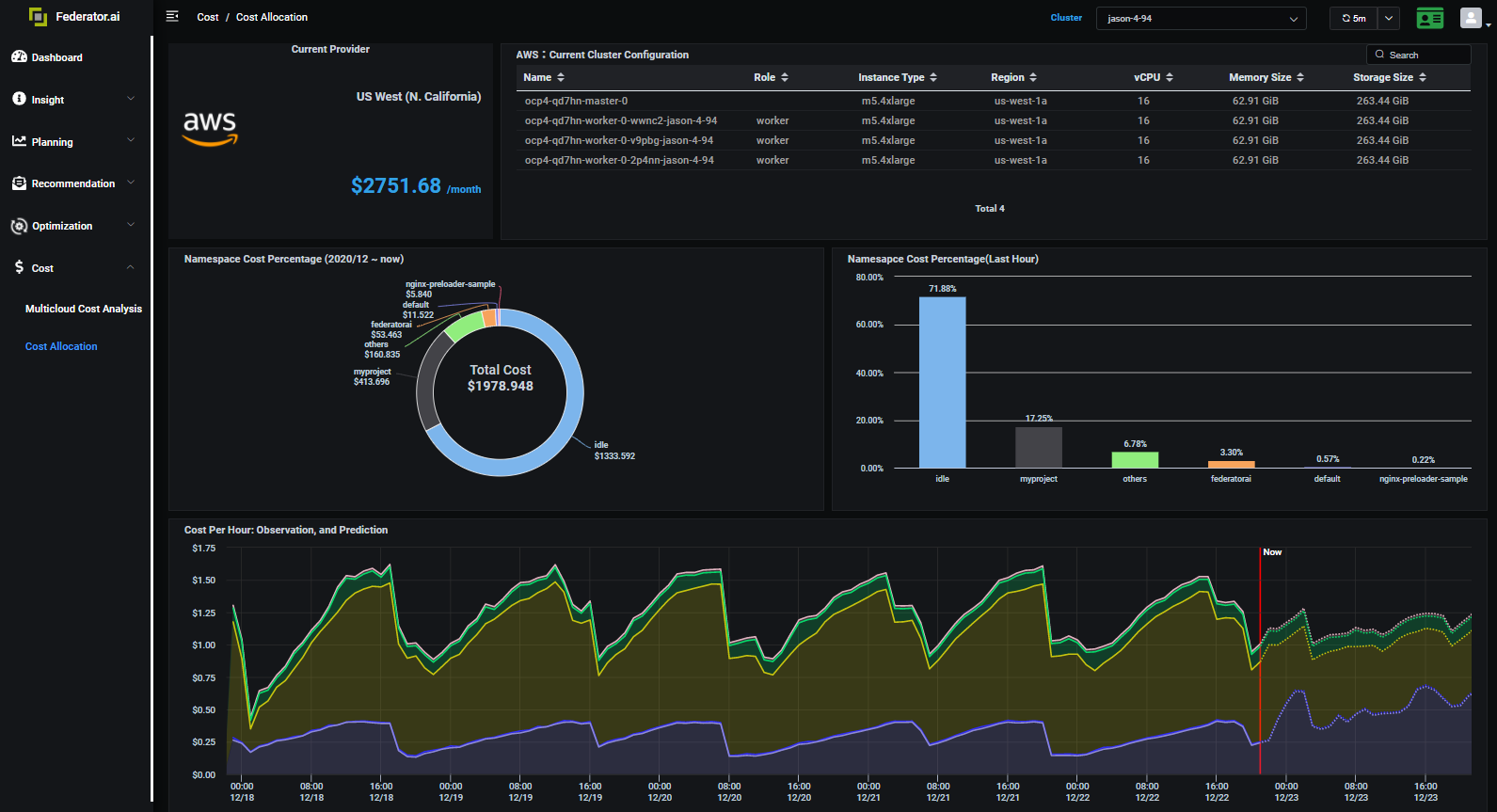
Federator.ai can further analyze your application usage and prediction to know the spent on different applications at the next level down.
In this example, you can see how much the system is wasting at idle when a cluster is over-provisioning. Federator.ai provides you recommendations on what instances types and the size of the cluster that optimize the cost with the workload prediction.
We continue to work with monitoring services/software and will have further updates. The proactive management with automation is a game-changer for adopting the OpenShift platforms on Premise and in Clouds. We have seen the adoption rate of cloud staying only close to 20%. With Federator.ai, we would like to provide a solution platform on the management plane to help answer questions, automate the management, optimize the performance and cost, and ease cloud adoption.