
{kind=link}

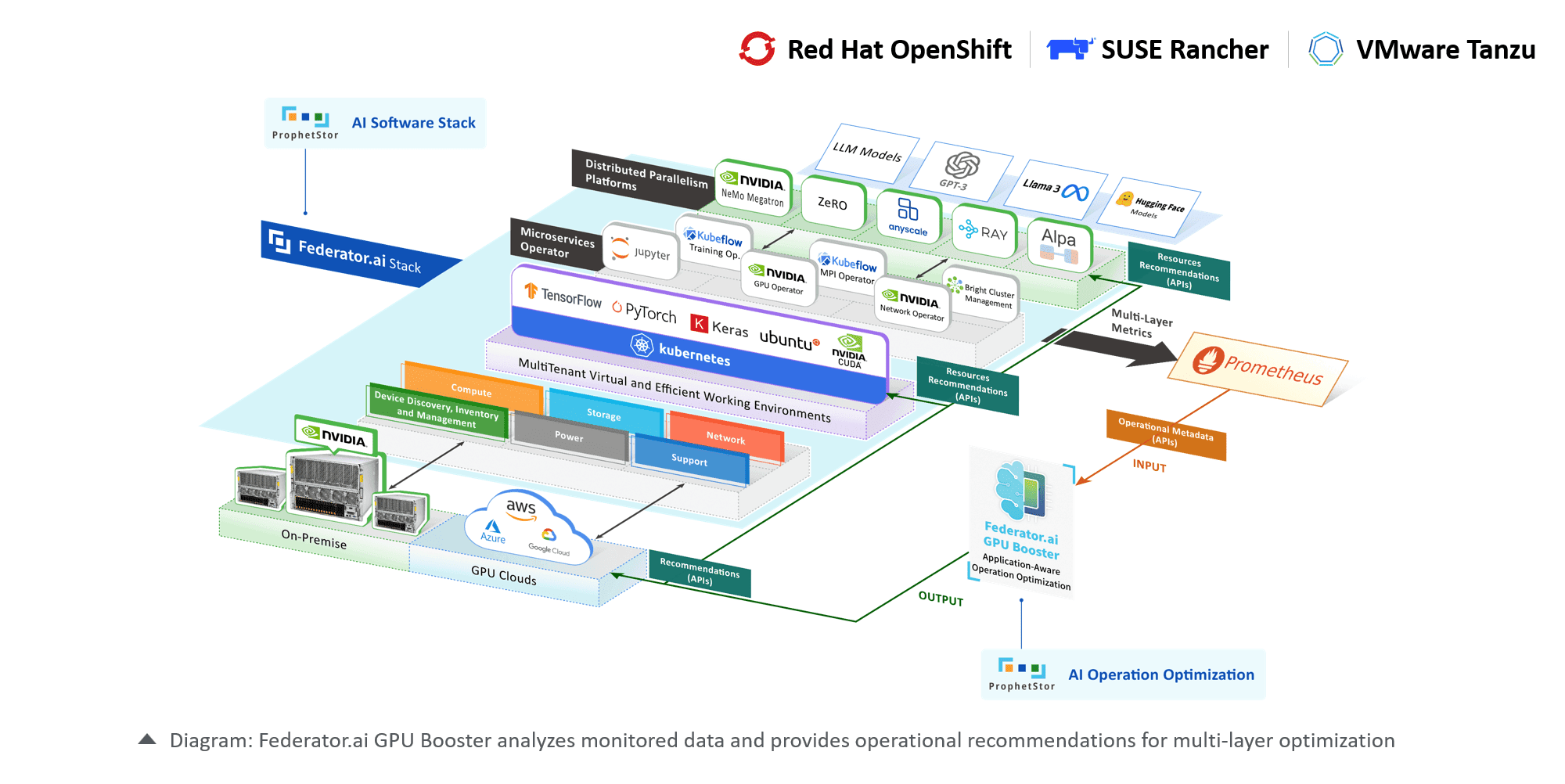
Full-Stack Visibility and Optimization
Tap into metadata and operational metrics from GPU hardware, the Kubernetes platforms, operators, AI/ML libraries, and frameworks to comprehensively view resource allocation and consumption, enabling informed resource optimization.
Hyper-Efficient Training Throughput
Agilely dispatch resources to support parallel MultiTenant AI/ML training and seamlessly migrate containerized applications in Kubernetes systems, avoiding performance disruption while significantly reducing training time and maximizing GPU utilization.

AI/ML Workload Pattern-Aware Insights
Leverage patented Spatial and Temporal GPU Optimization to multidimensionally predict resource needs for parallel AI/ML jobs, and use Cascade Causal Analysis to identify resource correlations for optimal, application-aware allocation.

ESG Compliance for Sustainability
Capture resource demands from bursty AI training traffic to efficiently allocate GPU resources for AI/ML workloads and intelligently manage cooling for GPU servers, ensuring high GPU utilization during AI training and reduced power consumption.