
Executive Summary
The Importance of GPU Resource Management in LLM Training
Advantages of Dynamic Over Static Resource Allocation
Key Findings and Technological Solutions Discussed
- Technological Solutions: Technologies like Kubernetes and Federator.ai GPU Booster are pivotal in enabling dynamic resource allocation. Kubernetes manages and scales containerized applications efficiently, while Federator.ai GPU Booster enhances these capabilities by predicting resource needs and optimizing allocation accordingly.
- Environmental and Economic Benefits: Dynamic allocation maximizes computational efficiency and promotes sustainability by reducing the energy consumption and carbon footprint associated with powering underutilized GPUs.
- Case Studies and Real-World Applications: The whitepaper includes case studies that demonstrates the successful application of dynamic resource allocation in various settings. These highlight significant improvements in resource utilization rates, reductions in training time, and cost savings.
- Recommendations for Implementation: The whitepaper provides actionable recommendations for organizations looking to adopt dynamic resource allocation. These include evaluating current resource management practices, investing in relevant technologies, and continuously monitoring and optimizing resource usage.
Introduction
Definition and Significance of Large Language Models (LLMs)
Overview of Challenges in GPU Resource Management During LLM Training
- Scalability: The size and complexity of LLMs have grown exponentially, requiring more powerful and numerous GPUs. Efficiently managing this scaling is crucial to maintain feasible training times and costs.
- Cost Efficiency: GPUs are expensive, and their operation involves significant energy consumption and associated costs. Efficient use of GPU resources is crucial to minimize financial overheads and maximize output.
- Resource Allocation: Effectively managing GPU resources is challenging, especially with static resource allocation methods that cannot adapt to the fluctuating needs of LLM training programs.
- Energy Consumption: The environmental impact of running power-intensive GPUs for prolonged periods is a growing concern, necessitating more sustainable resource management practices.
Objectives and Scope
This whitepaper addresses these aforementioned challenges by advocating for dynamic resource allocation as a superior alternative to traditional static methods. The objectives of this whitepaper are:
- To Highlight the Importance of Dynamic Resource Allocation: This paper aims to demonstrate how dynamic allocation can efficiently meet the variable demands of LLM training, reducing wastage and adapting to the workload in real-time.
- To Review Technological Solutions: The paper discusses advanced technologies such as Kubernetes and Federator.ai GPU Booster, which facilitate dynamic GPU resource allocation, enhancing operational efficiency and cost-effectiveness.
- To Provide Actionable Insights and Recommendations: Through case studies and empirical data, the whitepaper offers actionable insights for organizations looking to improve their resource management practices, thus aligning operational efficiency with environmental sustainability.
- To Foster Industry Best Practices: By showcasing the benefits and successful implementations of dynamic resource allocation, the whitepaper encourages more comprehensive adoption of these practices in the industry, aiming to set new standards in resource management for AI development.
Overall, the whitepaper seeks to empower stakeholders by providing a detailed understanding of dynamic resource allocation benefits backed by real-world applications and data. Thus, it aims to pave the way for more informed decision-making and strategic planning in AI development environments.
Understanding GPU Demands in LLM Training
Detailed Analysis of GPU Resource Requirements Across Different Training Phases
Initial Training Phases (Early Epochs): During the early stages of training Large Language Models (LLMs), the models require a high learning rate to explore the solution space rapidly. This phase is characterized by:
- High Learning Rate: Enables fast initial learning but requires frequent updates to the model’s weights, significantly increasing computational demand.
- Intensive GPU Utilization: The need for large batch sizes and high-frequency updates during this phase demands substantial parallel processing capabilities, requiring extensive GPU resources.
- Parallel Training Needs: Techniques such as data parallelism and model parallelism are employed to distribute the workload effectively across multiple GPUs. This aims to reduce training time and manage large datasets efficiently.
Middle Stages of Training: As the training progresses, adjustments are made to optimize the learning process:
- Adjustment of Learning Rate: Gradually reducing the learning rate refines the model’s weights more precisely, decreasing the demand for GPU resources.
- Gradual Decrease in GPU Demand: The reduced frequency and magnitude of weight updates lessen the strain on GPU resources, potentially allowing for reduced resource allocation without compromising performance.
- Efficiency in Training: Optimization techniques such as mixed-precision training can enhance computational efficiency, further reducing GPU usage.
Later Stages (Approaching Convergence): In the final stages of training, the focus shifts to refining the model to achieve optimal performance:
- Fine-tuning and Lower Learning Rates: Low learning rates are used for minor adjustments to the model, requiring less computational power.
- Minimal GPU Utilization: The demand for GPU resources significantly diminishes as the model stabilizes and requires fewer updates.
- Focus on Specific Tasks: Specialized fine-tuning for tasks or sub-tasks may involve only parts of the model, potentially allowing for partial GPU utilization.
Variability in GPU Demands Between Epochs
Between epochs, GPU demands can fluctuate significantly due to various factors:
- Data Shuffling and Loading: At the start of each epoch, data must be shuffled and loaded, causing spikes in GPU usage as new data batches are prepared.
- Adjustments in Model Parameters: Learning rate adjustments and other parameter tweaks at the epoch boundaries can temporarily increase the GPU load as the model adapts to these new settings.
- Evaluation and Validation Checks: Models are often evaluated against validation sets at the end of epochs to monitor performance and prevent overfitting. Depending on the validation data’s size and the evaluation metrics’ complexity, this can be computationally intensive.
How Federator.ai GPU Booster Can Help
Federator.ai GPU Booster can significantly enhance the management of GPU demands throughout the training of LLMs by:
- Predictive Resource Allocation: Leveraging advanced predictive analytics, Federator.ai GPU Booster forecasts the GPU requirements of different training phases and dynamically allocates resources accordingly. This ensures GPUs are fully utilized when needed and conserves resources when demand wanes.
- Real-time Adaptability: The system adjusts GPU allocations in real-time in response to changes in workload demands, such as transitions from high to low learning rates or between data shuffling phases.
- Optimization of Resource Usage: By optimizing GPU utilization and managing power consumption effectively, Federator.ai GPU Booster helps reduce operational costs and environmental impact, addressing the challenges highlighted in studies like those conducted by Shanghai AI Laboratory.
Incorporating Federator.ai GPU Booster into the LLM training pipeline optimizes resource usage. It significantly enhances overall training efficiency, making it an essential tool for organizations aiming to streamline their AI development workflows.
Electricity and the Insufficiency of It
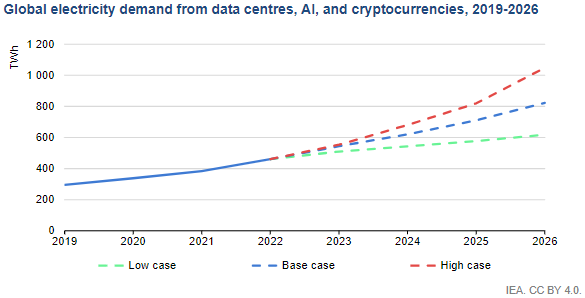
Highlight the Inefficiencies in Static Resource Allocation Using Examples from the Literature
- Underutilization: During periods of low computational demand, such as in the later stages of training or between epochs, statically allocated GPUs may remain idle, resulting in wasted resources.
- Inflexibility: Static allocation does not account for the peak demands during the initial training phases or at epoch transitions, potentially leading to bottlenecks that slow down the training process.
- Increased Costs: Maintaining unused or underutilized GPUs can lead to unnecessarily high operational costs, especially in cloud environments where resources are billed per usage.
Benefits of Dynamic GPU Resource Allocation
Adaptability to Real-Time GPU Demand Fluctuations
Dynamic GPU resource allocation provides a responsive and flexible framework that adjusts the amount of GPU power allocated to tasks based on the LLM workload behaviors. This adaptability is crucial for training LLMs, where computational demands can vary dramatically throughout different phases of the training process. Key aspects of this adaptability include:
- Real-Time Monitoring and Behavior-Based Adjustment: Dynamic systems continuously monitor the workload and automatically adjust the allocation of GPU resources. This ensures that resources are not idle when demand is low and are readily available when computational needs spike, such as during the initial training phases or when processing large batches of data.
- Responsive Scaling: In response to changes detected in workload demands, predictive and dynamic allocation systems can scale GPU resources up or down. This feature is particularly beneficial in cloud-based environments where the ability to scale resources dynamically can lead to significant cost savings and enhanced performance.
Cost Efficiency Through Precise Resource Allocation
One of the most compelling advantages of dynamic GPU resource allocation is the potential for reduced operational costs through more precise resource management. Benefits in this area include:
- Reduction in Resource Wastage: Dynamic systems prevent the financial drain associated with underutilized resources by allocating GPUs only when needed. This is especially important given the high cost of GPU units and the expenses related to powering and cooling these devices.
- Optimized Resource Spending: Dynamic allocation allows organizations to pay only for their GPU resources they actually use, which is an optimal approach for managing budget constraints in cloud computing environments. This method contrasts sharply with static allocation, where resources must be paid for regardless of whether they are fully utilized.
Performance Enhancement Through Optimal Resource Utilization
- Minimizing Bottlenecks: By allocating more resources during peak demand times, dynamic systems prevent bottlenecks that could delay the training of LLMs. This is critical during the early stages of model training, where rapid iteration is necessary for efficient learning.
- Enhancing Training Speed: Efficient resource allocation can significantly reduce the time required to train models by ensuring that GPU resources are available when it is most needed. Thus, computations are speeded up, and overall training time is reduced.
- Maintaining System Balance: In multi-tenant environments or platforms hosting multiple training tasks simultaneously, dynamic allocation helps maintain system balance by ensuring that no single task monopolizes GPU resources to the detriment of others.
Dynamic Allocation in Action: Case Studies and Real-World Applications
Introduction to Dynamic Allocation Technologies
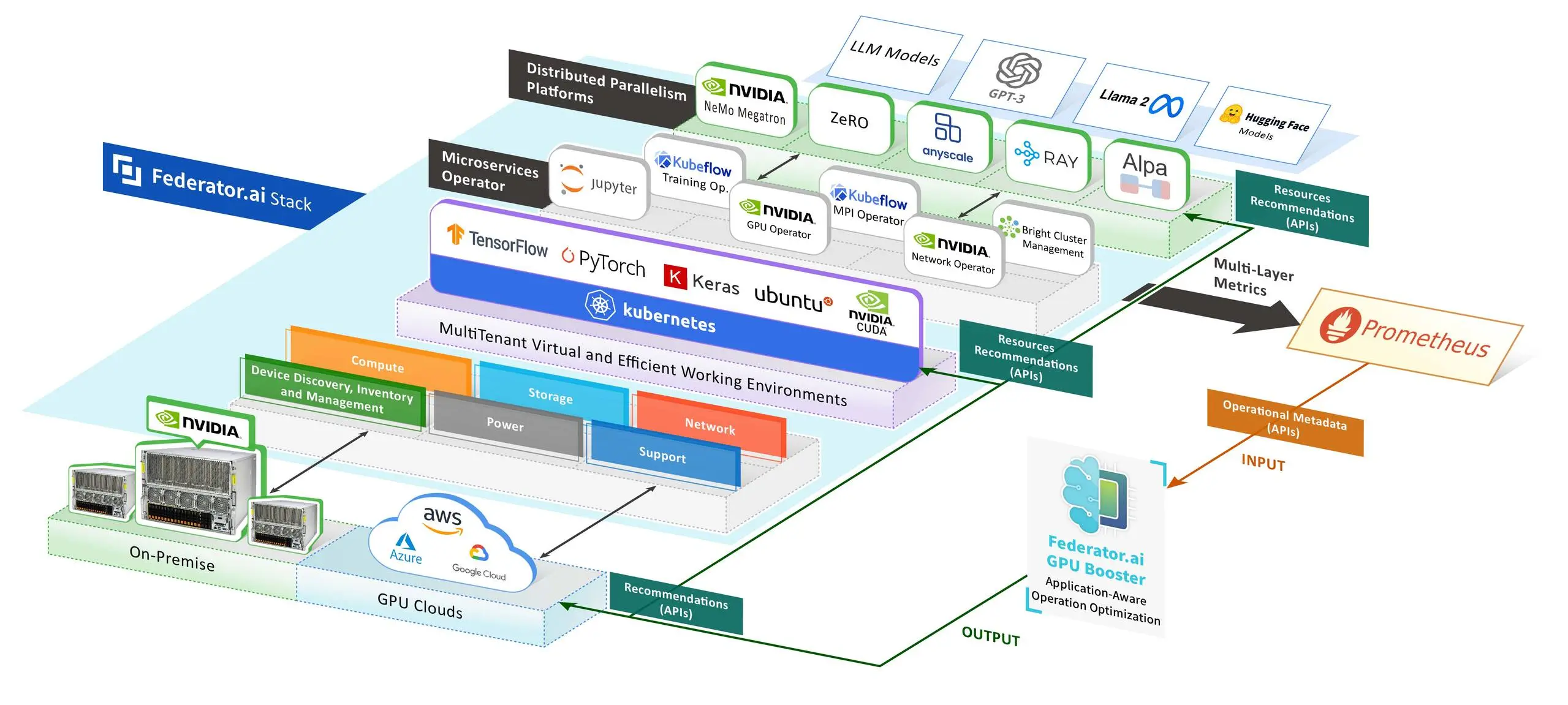
Dynamic allocation technologies are crucial for managing the complexities of resource allocation in environments that demand high computational power, such as training Large Language Models (LLMs). These technologies enable flexible and efficient use of GPU resources, adapting to real-time needs and optimizing performance and cost.
Kubernetes: Kubernetes is an open-source system for automating containerized applications’ deployment, scaling, and management. It excels in managing and scheduling GPU resources in a cloud environment, offering the following key features:
- Dynamic Resource Scheduling: Kubernetes can dynamically schedule GPU resources to different nodes based on workload demands, ensuring that resources are efficiently utilized without over-provisioning.
- Automated Scalability: It allows for the automatic scaling of GPU resources, adjusting the number of active GPUs according to the current needs of the training process, which is particularly beneficial during variable intensive phases of LLM training.
- Resource Isolation and Management: Kubernetes provides excellent isolation and management of GPU resources, ensuring that multiple training models can run simultaneously without interference, thus maximizing resource utilization.
Federator.ai GPU Booster: Developed by ProphetStor, Federator.ai GPU Booster is designed to enhance GPU management in multi-tenant environments. It offers advanced predictive analytics and real-time resource allocation capabilities:
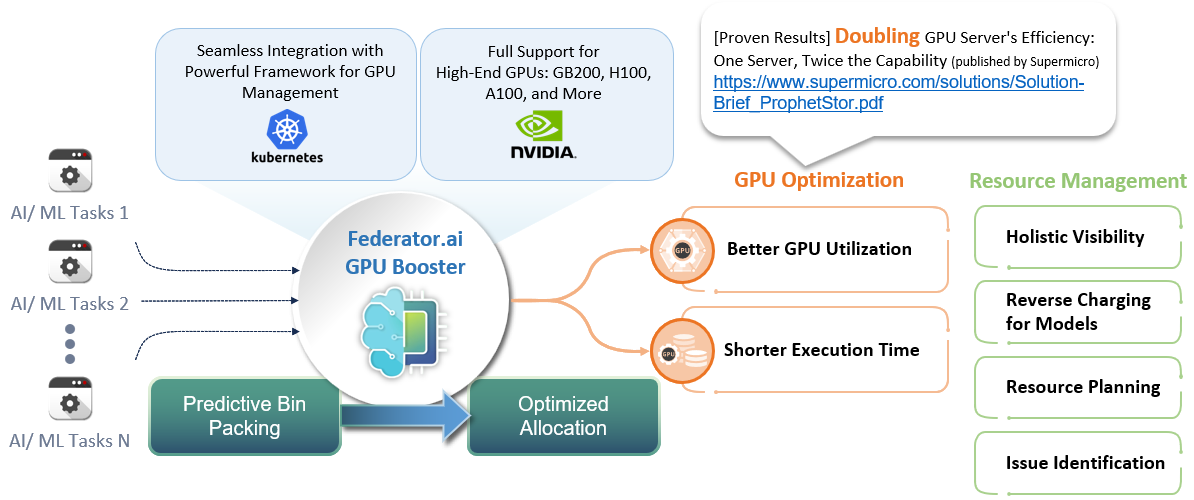
- Predictive Resource Allocation: This method utilizes machine learning algorithms to predict future resource requirements, allowing it to allocate GPU resources proactively before they are needed.
- Optimized Resource Utilization: By understanding usage patterns and predicting future demands, Federator.ai GPU Booster ensures that GPUs are optimally utilized, significantly improving efficiency and reducing wastage.
- Integration with Kubernetes: Federator.ai GPU Booster integrates seamlessly with Kubernetes, enhancing its native capabilities by adding a layer of intelligence that predicts and manages GPU resources more effectively.
Case Studies and Data
- Supermicro and Federator.ai GPU Booster Integration:
- Scenario: A case study involving Supermicro servers equipped with NVIDIA HGX H100 GPUs showcased the integration of Federator.ai GPU Booster.
- Results: The deployment of Federator.ai GPU Booster reduced job completion times by 50% and doubled the average GPU utilization efficiency. This demonstrates substantial improvements in both performance and resource efficiency.
- Kubernetes in AI/ML Workloads:
- Scenario: Kubernetes managed and scheduled AI/ML workloads, including those for training LLMs.
- Results: Kubernetes enabled better resource scalability and efficiency, particularly in environments with fluctuating workload demands. It helped reduce resource contention and improved the overall throughput of training operations.
- ProphetStor’s Federator.ai GPU Booster in MultiTenant Environments:
- Scenario: In a multi-tenant cloud environment, Federator.ai GPU Booster managed GPU resources across various user groups and applications.
- Results: It minimized job queuing times and enhanced GPU utilization rates by dynamically adjusting resources based on predictive analytics. This led to more efficient use of expensive GPU assets and reduced operational costs.
In comparison with Traditional Static Resource Managers like Slurm
Traditional resource managers like Slurm are typically configured for static resource allocation. While Slurm is highly effective in environments with predictable workloads, it lacks the flexibility to adapt to the variable computational demands inherent in LLM training.
Differences include:
- Flexibility: Slurm allocates resources based on pre-configured settings and does not dynamically adjust to changes in workload demands, potentially leading to underutilization or bottlenecks. In contrast, Kubernetes and Federator.ai GPU Booster adjust resources based on real-time usage.
- Scalability: Dynamic systems can automatically scale resources up or down, while static systems like Slurm require manual reconfiguration to change resource allocations.
- Cost Efficiency: Dynamic resource allocation reduces costs by minimizing resource wastage, whereas static allocation might incur costs for idle resources.
The Critical Role of Time Series Dynamic Programming Bin Packing (TS-DPBP)
The Federator.ai GPU Booster’s patent-pending resource optimization solution, the Time Series Dynamic Programming Bin Packing (TS-DPBP) approach, integrates the temporal dimension into the resource allocation. This is particularly crucial for applications like LLM training, where resource needs change over time. This method optimizes not just the allocation of resources at a single point in time but across a sequence of time slots, considering past and predicted future demands.
Unique features of TS-DPBP include:
- Optimization Over Time: Unlike traditional bin packing that only considers the spatial aspect (packing items into bins to minimize unused space), TS-DPBP also considers time, adjusting allocations dynamically as needs evolve.
- Predictive Analytics: By forecasting future demands, TS-DPBP ensures that resources are prepared to meet peak demand, enhancing efficiency and reducing the likelihood of resource shortages.
- Integration Potential: TS-DPBP can be integrated with technologies like Kubernetes and Federator.ai GPU Booster to enhance its effectiveness. This combination of spatial and temporal resource optimization provides a comprehensive solution.
Overall, dynamic allocation technologies supported by the predictive capabilities of systems like Federator.ai GPU Booster and methodologies like TS-DPBP represent the most advanced solutions for managing modern computational tasks’ complex, fluctuating demands. These systems offer advantages over traditional static resource managers by improving flexibility, efficiency, and cost-effectiveness in resource-intensive environments.
Conclusion
Summary of the Advantages of Dynamic Resource Allocation for LLM Training
The exploration and analysis presented in this whitepaper underline the significant advantages of dynamic resource allocation systems over traditional static methods, especially in the context of training Large Language Models (LLMs). These advantages are critical in driving efficiency, reducing costs, and enhancing the performance of computational systems required for LLM training. Key benefits include:
- Adaptability to Fluctuating Demands: Dynamic resource allocation systems like Kubernetes and enhancements from technologies like Federator.ai GPU Booster provide unparalleled flexibility. They adjust GPU resources in real-time based on the varying needs of LLM training phases, ensuring that resources are not wasted during low-demand periods and are sufficiently available during peak demands.
- Cost Efficiency: Dynamic systems significantly reduce operational costs by optimizing expensive GPU resources. They ensure that resources are only consumed as needed, which is particularly beneficial in cloud-based environments where resource usage directly impacts financial expenditure.
- Enhanced Performance: These systems improve the performance of LLM training programs by preventing resource bottlenecks and enabling faster computation times. This leads to quicker model training cycles, allowing organizations to accelerate their AI development and deployment timelines.
- Scalability and Flexibility: The ability to scale resources up or down without manual intervention makes dynamic resource allocation ideal for handling the complex and unpredictable nature of AI and machine learning workloads. This scalability is essential for supporting the growth of AI initiatives without corresponding increases in complexity or cost.
Call to Action for Adopting Smarter Resource Management Solutions
In light of these insights, it is evident that adopting more innovative resource management solutions is beneficial and essential for organizations looking to stay competitive in the rapidly evolving field of artificial intelligence and machine learning. To effectively harness the benefits of LLMs and other AI technologies, companies must transition away from outdated static resource management methods and embrace dynamic systems that can fully leverage the capabilities of modern computing infrastructure.
Recommendations for Implementation:
- Evaluate and Integrate Dynamic Resource Management Systems: Organizations should assess their current resource management frameworks and consider integrating systems like Kubernetes and Federator.ai GPU Booster. This integration will immediately improve resource utilization and cost management.
- Invest in Training and Development: Ensure IT teams are well-versed in operating and maintaining dynamic resource allocation systems. Training will help maximize the benefits of these technologies.
- Monitor and Optimize Continuously: Adopt a continuous improvement approach to resource management. Regularly analyze the performance of your resource allocation strategies and make adjustments based on evolving training needs and technological advancements.
- Engage with Expert Partners: Consider partnerships with technology providers offering expertise and support in implementing dynamic resource allocation solutions tailored to your needs.
By shifting towards more adaptive, efficient, and intelligent resource management systems, organizations can improve the efficiency of their LLM training initiatives and set a foundation for broader AI and machine learning strategies. This strategic pivot is not merely an upgrade but a transformative shift that will define the future landscape of AI development and deployment.
References
In this section, we consolidate and cite all the sources and documents referenced throughout the whitepaper to acknowledge their contributions and enable readers to access further details. This includes the uploaded documents, authoritative articles, case studies, and any additional literature used to support the discussions in the whitepaper. Here is how you might format and detail these references:
- Liu, Y., et al. (2024). “Understanding LLMs: A Comprehensive Overview from Training to Inference.” arXiv preprint arXiv:2401.02038. Retrieved from https://arxiv.org/abs/2401.02038.
- This paper extensively reviews the techniques and technologies involved in large language models’ training and inference phases (LLMs), highlighting their evolution and impact on artificial intelligence.
- Super Micro Computer, Inc. (2024). Supermicro and ProphetStor Enable Better GPU Utilization. Retrieved from https://www.supermicro.com/solutions/Solution-Brief_ProphetStor.pdf
- Hu, Q. et al., (March 2024). Understanding the Workload Characteristics of Large Language Model Development. Retrieved from https://www.usenix.org/publications/loginonline/understanding-workload-characteristics-large-language-model-development
- Hu, Q., Ye, Z., Wang, Z., Wang, G., Zhang, M., Chen, Q., Sun, P., Lin, D., Wang, X., Luo, Y., Wen, Y., & Zhang, T. (2024). “Characterization of Large Language Model Development in the Datacenter.” arXiv preprint arXiv:2403.07648. Last revised April 2024 (version v2). Retrieved from https://doi.org/10.48550/arXiv.2403.07648
- This paper presents a comprehensive characterization study of a six-month LLM development workload trace from the GPU data center Acme. The study focuses on discrepancies between LLMs and traditional Deep Learning workloads, exploring resource utilization patterns and identifying impacts of various job failures. The authors discuss system improvements, including fault-tolerant pretraining and decoupled scheduling for evaluation, to enhance the efficiency and robustness of LLM development.
- Chen, L. & Chen, E. (2024). “Optimizing Resource Allocation Over Time: The Time Series Dynamic Programming Bin Packing (TS-DPBP) Approach.” Internal document, ProphetStor Data Services Inc., is available upon request.
- This white paper introduces the Time Series Dynamic Programming Bin Packing (TS-DPBP) approach. This novel method incorporates both time and space considerations into the resource allocation process, significantly enhancing the efficiency of dynamic resource management systems.
- ProphetStor Data Services Inc. (2024). “Solution Brief: Enhancing GPU Management in Multi-Tenant Environments with Federator.ai GPU Booster.” Retrieved from https://www.supermicro.com/solutions/Solution-Brief_ProphetStor.pdf
- This solution brief details Federator.ai GPU Booster’s capabilities, particularly its use in managing GPU resources in MultiTenant cloud environments. It includes case studies demonstrating the application of Federator.ai GPU Booster in conjunction with Supermicro’s GPU servers.
- (n.d.). “Kubernetes Documentation.” Retrieved from https://kubernetes.io/docs/home/
- The official Kubernetes documentation provides comprehensive information on deploying, managing, and scaling containerized applications with Kubernetes, including details on its dynamic resource allocation capabilities.
- University of Hong Kong. (n.d.). SLURM Guide. Retrieved from https://hpc.hku.hk/guide/slurm-guide/
- (n.d.). Cheat sheet for SLURM Job Scheduler. Retrieved from https://slurm.schedmd.com/pdfs/summary.pdf
- Documentation and resources describing the features and configurations of Slurm, a scalable workload manager commonly used in static resource allocation scenarios.