
The world’s most influential digital platforms, such as Amazon, Netflix, Facebook, LinkedIn, etc., constantly (machine) learn to offer better recommendations and advice. And it’s becoming clear that the best advice we now receive is more likely to come from intelligent machines than smart people [2,3]. “Recommender systems are the most important AI system of our time, the most important machine-learning pipeline today.,” Nvidia CEO and co-founder Jensen Huang said in Time Magazine in2021 [4]. “Recommender systems predict your needs and preferences from past interactions with you, your explicit preferences, and learned preferences using collaborative and content filtering methods.” Recommendation engines represent a global revolution in how choice can be personalized, packaged, presented, experienced, and understood.
With recommendation engines (we will use Recommendation Systems and Recommendation Engines interchangeably) in the consumer world, people can make impactful decisions based on the deeper insights and recommendations unseen before. However, although the recommendation engines are readily available in the consumer sector, the IT world is yet to have one that helps the user automate and optimize operations in Cloud, which is deemed complicated to do and requires certified cloud architects and engineers’ involvement.
The State of Digital Transformation
ProphetStor’s DataProphet Recommendation Engine Is the Core of the Optimization Solution

Solutions for Stages of Cloud Adoptions
Visibility
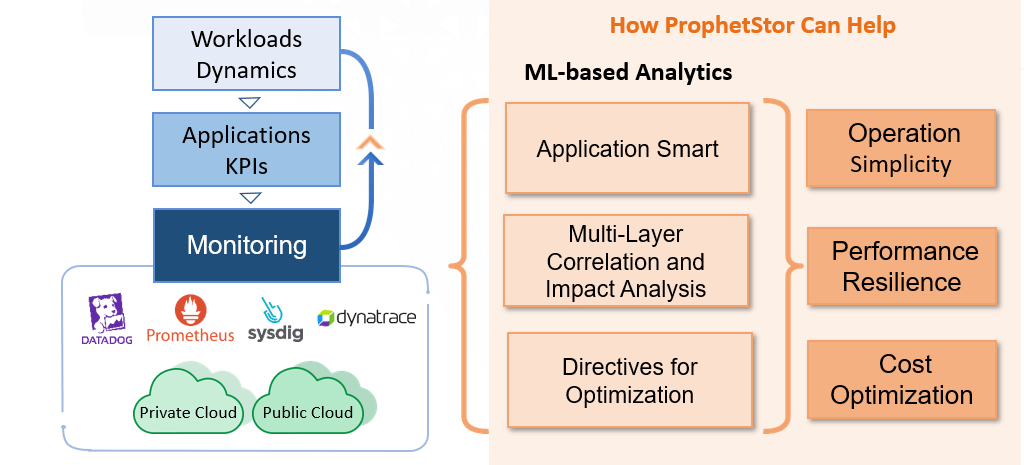
Datadog, Prometheus, Sysdig, Splunk, Dynatrace, etc., are the leading solution providers of visibility in the Cloud. They offer a single pane of glass to present the data collected from multiple sources, visualize the operation data, and provide clues of operation trending information. This approach helps customers regain visibility and present the data scattered initially to multiple visibility solutions previously.
Cloud service providers also offer monitoring services and solutions to customers. Examples are Azure Monitoring, Cloud Watch (AWS), Green Lake (HP), Cloud Monitoring (Google), etc. Because the data collected are limited to the instances (such as the utilization of resources in the instances). They do not offer the metrics related to applications, virtualization platforms, logs and traces from various elements, and correlations for workload dynamics. They could not be effectively used in planning, issue isolations, and mitigations. In addition, these solutions do not offer recommendations for users to decide on the choices of resources for application resilience and performance acceleration.
Security
Efficiency
The ways to use resources in the Cloud and on-prem are very different. In the conventional on-prem infrastructure, it takes weeks, if not months, to procure, install, configure, and integrate the equipment before it can be operational. It is less likely that the resources can be adapted to the dynamic nature of the workload. In addition, the sunk cost of the on-prem equipment makes it less necessary to watch for the efficient usage of the resources.
On the other hand, when the applications are running in the Cloud, the cost of operation relies on the hour-by-hour, or even minute-by-minute, usage of the cloud resources. The cost of the operation can only be contained by changing the mindset from the CAPEX to the OPEX-based. As a result, in an enterprise, it is everyone’s responsibility to take care of the cost of operation and the visibility of the operation, and the adaptation of the resources to achieve the seemingly conflicting objectives of operation resilience and cost becomes complicated.
Many users adopted an over-provisioning strategy to resolve the resilience issues by allocating fixed and much larger resources than necessary, hoping to avoid service disruptions. It defeats the purpose of OPEX, and a simple spike in the workload might also cause the application to stop due to insufficient resources.
ProphetStor’s mission is to optimize the performance and cost of cloud operations in a machine-based, proactive manner. Federator.ai takes the operation metadata, analyzes and discovers the correlation and impacts, (machine) learns and builds operation models, and recommends the resource allocation and orchestration for the operation residence and efficiency.
During this process, we resolved many issues that deemed computational hard to get a viable solution:
- Conventional data science approaches look for correlations of ALL data sources. The approach inevitably becomes computation-intensive to process the time series and multiple data sources in multi-layers. ProphetStor’s DataProphet Recommendation Engine focused on multi-layer correlations from top to bottom, avoiding unnecessary calculations for finding relations of sources not needed in decision-making. The resulting solution saves more than 1,000 times of computation needed for an effective recommendation engine to develop actionable directives. For a detailed description of the multi-layer correlation, please see the whitepaper in [7].
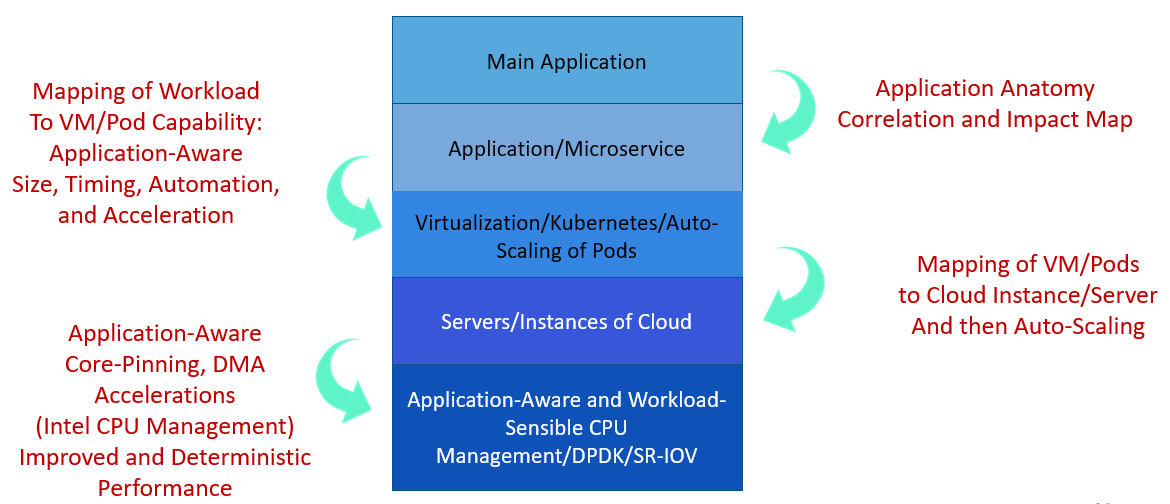
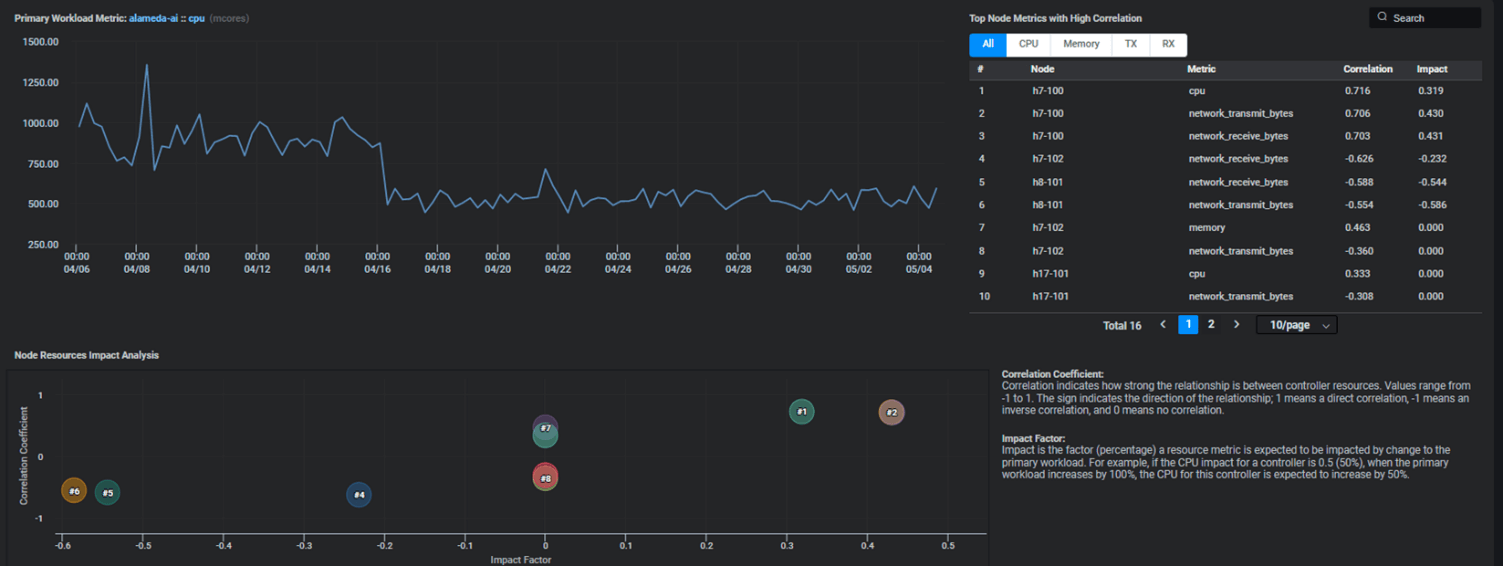
- ProphetStor’s CrystalClear Time Series Analysis Engine is up to 23 times more efficient than the Facebook Prophet [5] and LinkedIn Greykite [6], with much better Mean Average Percentage Error (MAPE) as shown in [7], for use in the Multi-Layer correlation computations.
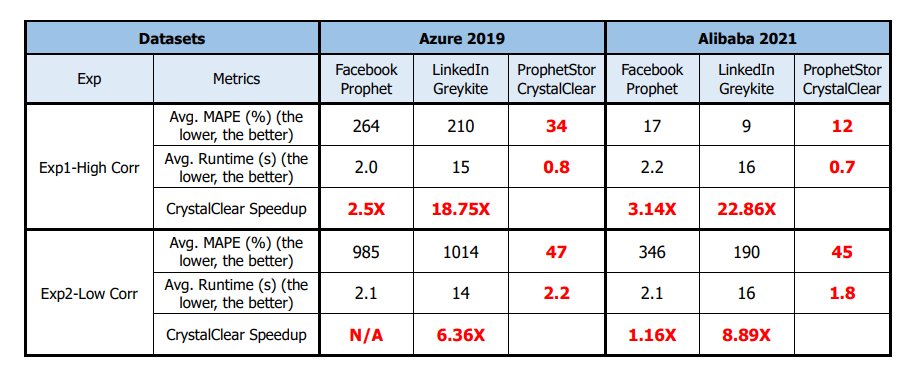
Combining the above points 1 and 2, Federator.ai has a cost-effective and computationally feasible solution to become a scalable solution in a full-stack insight and service or data mesh suitable solution that saves 1000s of computation time and makes the recommendation engine feasible.
With ProphetStor’s DataProphet Recommendation Engine, we can turn the passive management that waits for issues to happen into a proactive resource orchestrator that addresses both the resilience and the cost of operation in the next phase of the IT journey to Cloud Native.
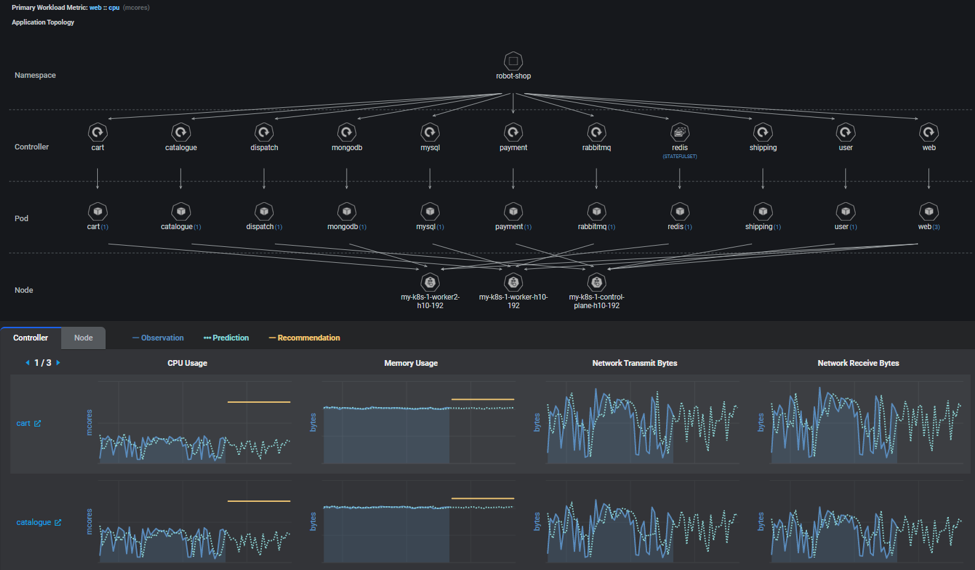
The DataProphet Recommendation Engine is an innovative way of handling the so-called North-South Insight (among layers of the IT infrastructure from application down to server/Cloud instance) and East-West Dynamics (how the applications/microservices react to the workload dynamics). In addition, we further consider time-based analysis to have the foresight of the dynamics for the future. As a result, this is a truly comprehensive platform that serves as a foundation for working with other market solutions. Again, without computation savings from the design, the full-scale insight into the past, present, and the future could not be economical enough to be helpful. Federator.ai, with DataProphet Recommendation Engine at its core, provides recommendations for operations.
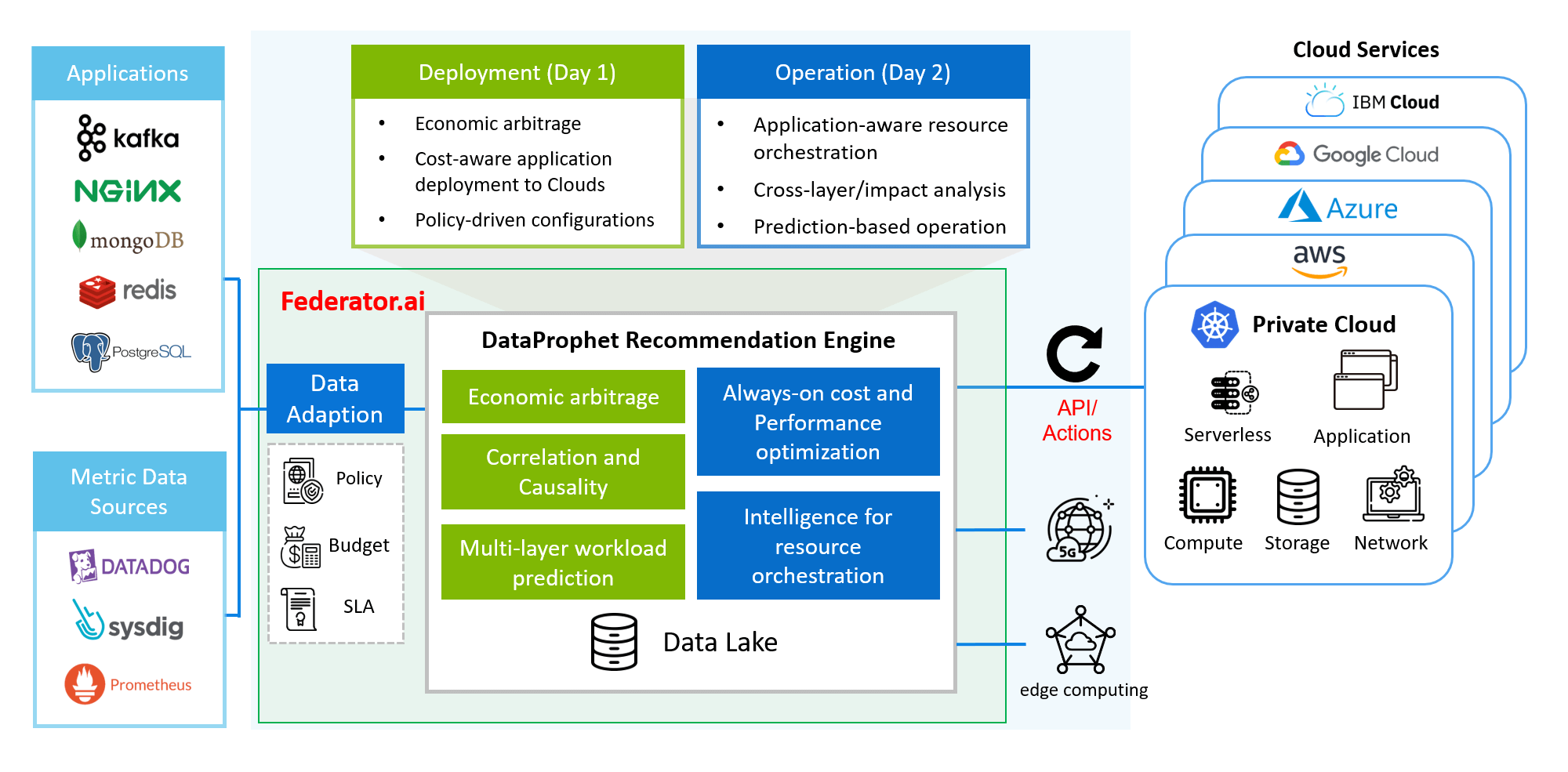

Here are some examples of application scenarios:
- Working with monitoring services/solutions, such as Datadog, Sysdig, Prometheus, Azure Monitoring, Cloud Watch (AWS), Green Lake (HP), Cloud Monitoring (Google), etc.: The DataProphet interacts with the data sources through a standard data adaptation layer via published APIs. DataProphet uses retained data from the monitoring solutions by fetching months of historical data without waiting for sufficient operation data to be collected. This dramatically shortens the time-to-value from days to hours. Federator.ai analyzes the collected metadata into intelligent operation recommendations to accelerate applications, enable planning, remove uncertainty, answer “what-if” questions for workload accommodations, and optimize the operation cost in an on-prem, hybrid cloud, or MultiCloud environment. In other words, Federator.ai can effectively turn visibility into continuous optimization in operations.
- Working with the service mesh [8] or data mesh [9] solutions, such as Istio, presto, and Kafka, to optimize the performance and minimize latency: The service mesh and data mesh solutions describe how the applications are interconnected and how the data is moved from among the applications. In addition, they implement the operation logic and the access security and control of the interconnections. With Fedeartor.ai, from the North-South Insight and East-West Dynamics analysis, Federator.ai complements the functions of the meshes by adding the complete insight and predictions of the dynamics of the applications. Federator.ai then helps accelerate the main application’s performance by automatically scaling the connected applications individually by removing the bottlenecks. The mesh provides the contract and connections among applications. However, the performance of the pipeline, in the case of Kafka, is determined by scaling the consumer’s application intelligently as the messaging services themselves do not consume many resources. A slow consumer will increase the latency (the lags) experienced by the messages. Since consumers can be producers of the following application in the pipeline, changing the dynamic will shift the bottlenecks. As a result, the optimization needs to be done by machine at the directive of the recommendation engine that understands the workload dynamics.

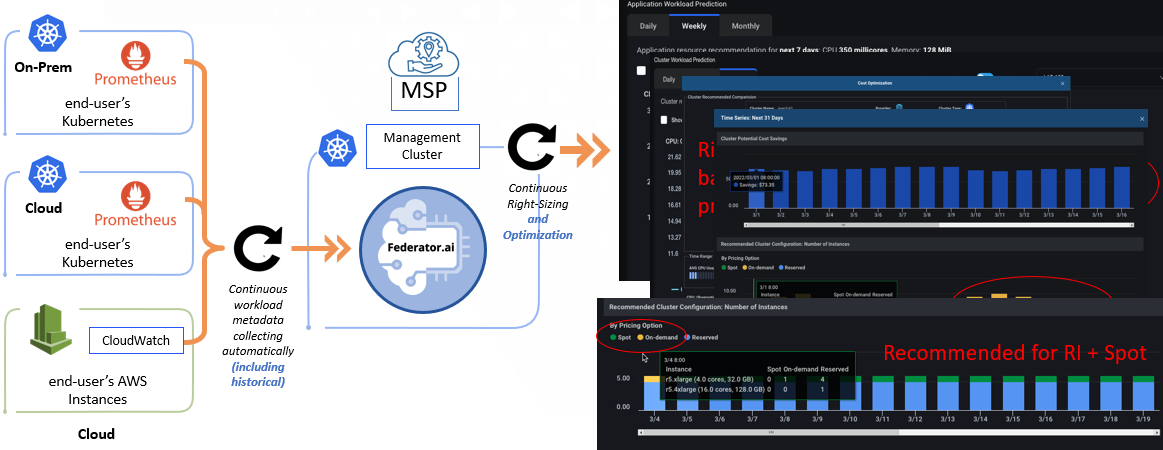
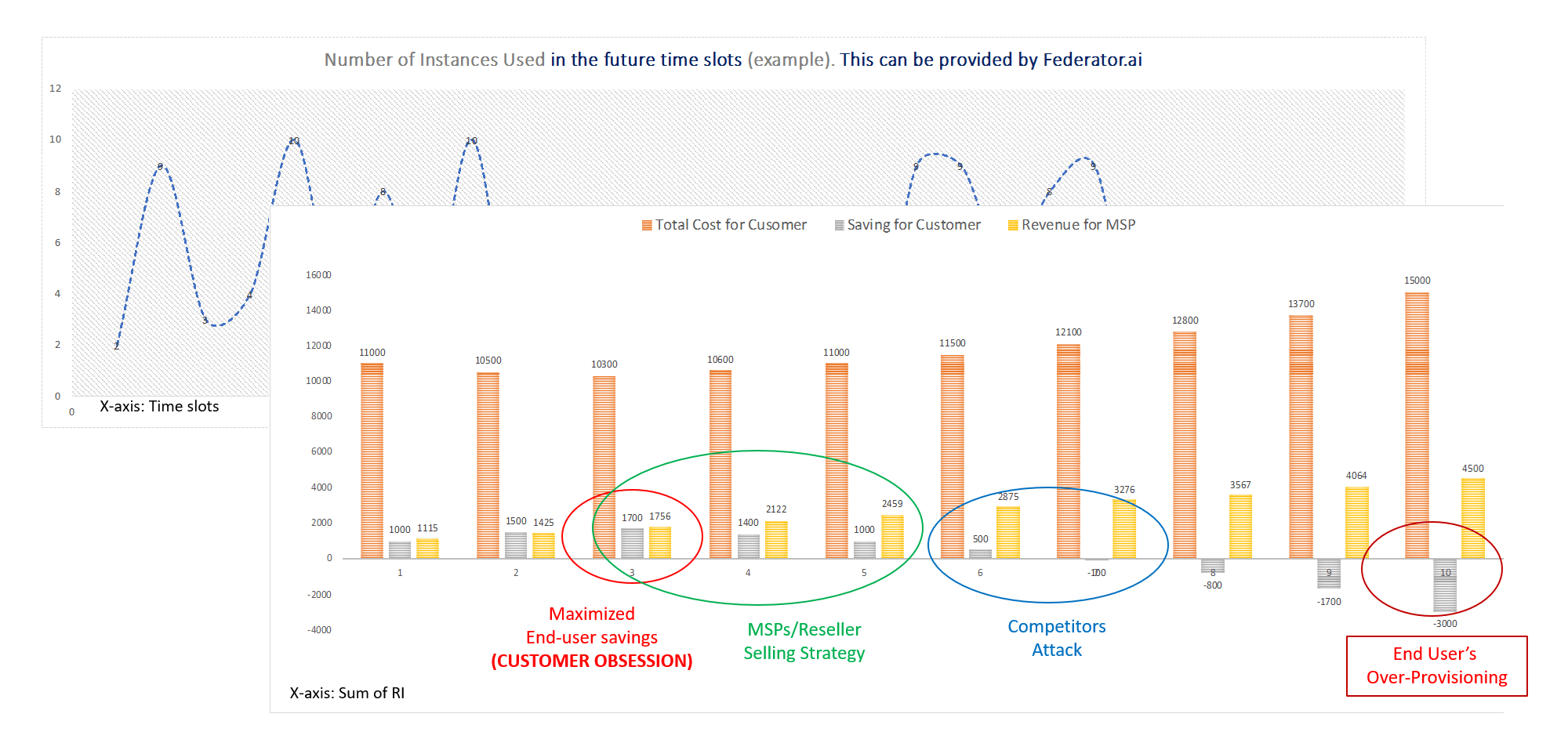
- For Cloud Managed Service Providers (MSPs) to offer value-added services automatically and achieve customer obsession: The MSPs offer the basic cloud service resells and advanced consulting services to ensure a smooth journey for the end-users. However, in the past, they lacked the total visibility of the cloud operations (as Cloud service provider’s tools, such as AWS’s CloudWatch), resulting in only billing analysis and instance utilization data for cost-saving recommendations. Also, without the awareness of the application-level operation metadata analysis, there is no way that the MSPs can present a meaningful classification of the workload for placements to On-Demand, Reserved, and Spot instances (all have very different discounts and margin structures). Furthermore, they cannot perform value-added services without a group of certified engineers for the cloud services and provide operation recommendations for application performance enhancement and resource planning. Federator.ai can provide the needed automation, perform the pivot analysis for application workload placements, and place the workloads intelligently to optimize the performance and cost. MSPs can offer the services without incurring additional technical resources, which are already scarce on the market.
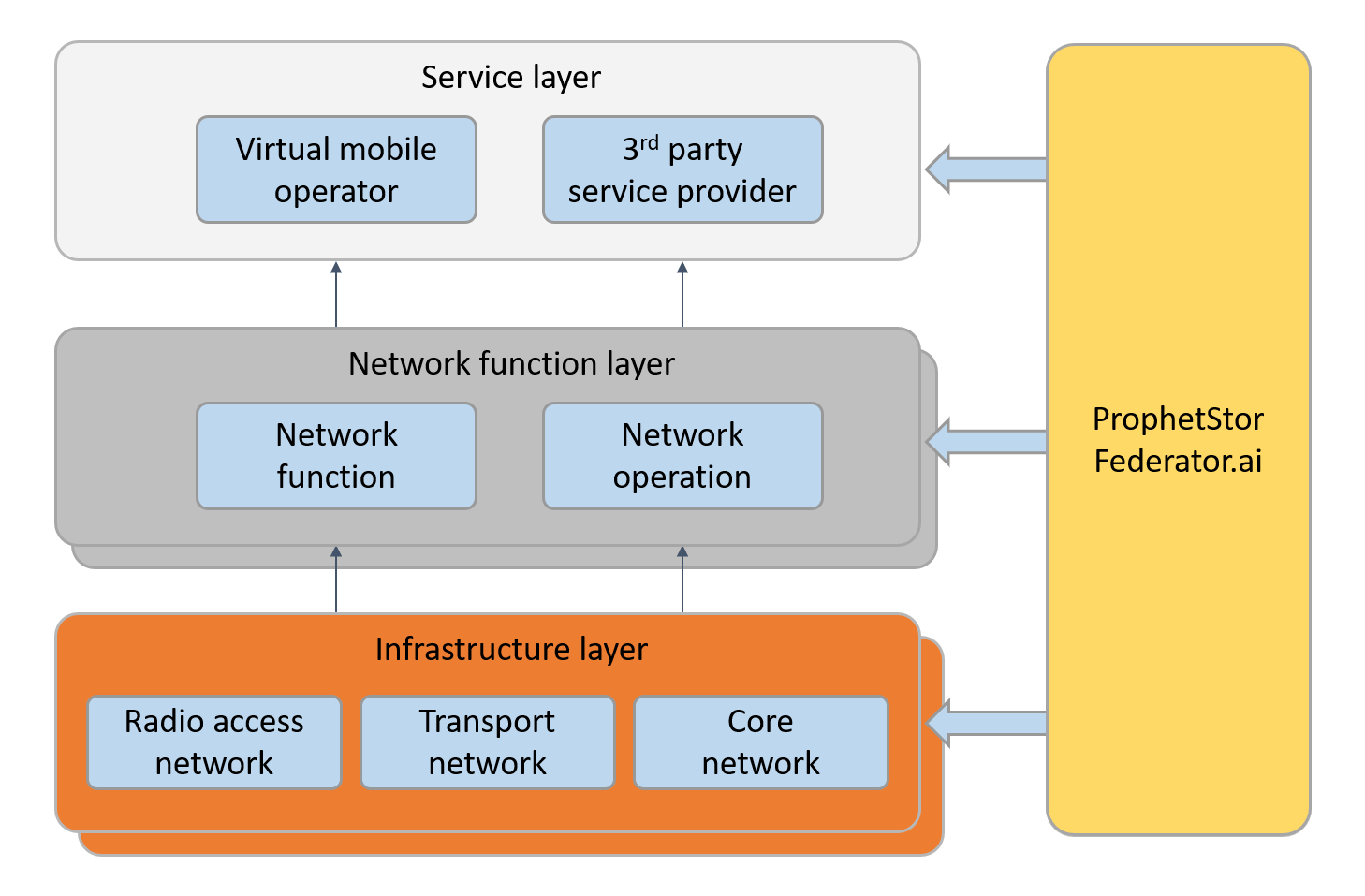
- For 5G service providers to meet application-level SLA by optimizing the application overlay: what can be applied in scenario 2 for cloud operation can be applied to the application overlay to support the needed application SLA. Federator.ai handls the multi-layer correlation (North-South Insight) and Service Mesh/Data Mesh performance optimization (East-West Dynamics). There are differences here as in 5G, the UPF functions in the core networks are in different backbone network nodes, whereas in the cloud case, the meshes provide the interconnections. However, without the complete stack insight and autoscaling to handle differences in application and network slices, it would not be easy to provide the guarantee for the SLAs specified for applications through different network segments.

References
- Francesco Ricci, Lior Rokach, Bracha Shapira, and Paul B. Kanto, eds., Recommender Systems Handbook (Springer, 2011).
- Michael Schrage, “The Recommender Revolution.” MIT Technology Review, April 27, 2022. Available from https://www.technologyreview.com/2022/04/27/1048517/the-recommender-revolution/
- Michael Schrage, Recommendation Engines, The MIT Press (September 1, 2020).
- “The Metaverse Is Coming. Nvidia CEO Jensen Huang on the Fusion of Virtual and Physical Worlds.” Time, April 18, 2021, Available from https://time.com/5955412/artificial-intelligence-nvidia-jensen-huang/
- Facebook, “Forecasting at Scale.” Available from https://facebook.github.io/prophet/
- LinkedIn, “Greykite: A Flexible, Intuitive and Fast Forecasting Library.” Available from https://github.com/linkedin/greykite
- ProphetStor, “Correlation-based Predictions for Kubernetes Resource Management. Available from https://prophetstor.com/white-papers/correlation-based-predictions/
- Istio, “The Istio service mesh.” Available from https://istio.io/latest/about/service-mesh/
- Confluent, “What Is Data Mesh?” Available from https://developer.confluent.io/learn-kafka/data-mesh/intro/
- Mohammad Shahrad, et al. “Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider.” in Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, Boston, MA, July 2020.
- Shutian Luo, et al. “Characterizing Microservice Dependency and Performance: Alibaba Trace Analysis.” In ACM Symposium on Cloud Computing (SoCC’ 21), November 1–4, 2021, Seattle, WA, USA. ACM, New York, NY, USA, 15 pages.
- Facebook, “Forecasting at scale.” Available from https://facebook.github.io/prophet/
- LinkedIn, “Greykite: A flexible, intuitive and fast forecasting library.” Available from https://github.com/linkedin/greykite