
What Is Federator.ai GPU Booster Inference?
Enterprises deploying large-scale LLMs like DeepSeek-R1 (671B) on 8×H20 GPUs face a critical memory cliff: less than 13% of GPU memory remains for KV cache, activations, and overhead. Without dynamic optimization, consequences include:
- Each OOM event causes 3–5 minutes of complete service outage
- 5–10 OOM events per hour can result in up to 66% downtime
- Conservative GPU operation at 60–70% wastes expensive hardware capacity
- Sudden workload spikes (e.g., Chinese-language queries requiring 2.5× more memory) destabilize static deployments
Federator.ai GPU Booster Inference—with native support for DeepSeek-R1 and NVIDIA GPUs—delivers zero-downtime, high-performance LLM inference by replacing fragile, static settings with continuous, autonomous optimization. It significantly increases throughput, reduces latency variability, eliminates OOM (out-of-memory) failures, and safely drives GPU memory utilization into the mid-90% at enterprise scale.
>60%
>95%
Zero
Core Technologies Powering Federator.ai GPU Booster Inference
Auto Kaizen™
Zero-OOM multi-layer protection
Memory Walking Technology
4-level observability
Benefits of Federator.ai GPU Booster Inference
Higher Throughput & Lower Latency
Zero-Downtime Reliability
Max GPU ROI
Predictable, Fast Rollout
Scales with Your Business
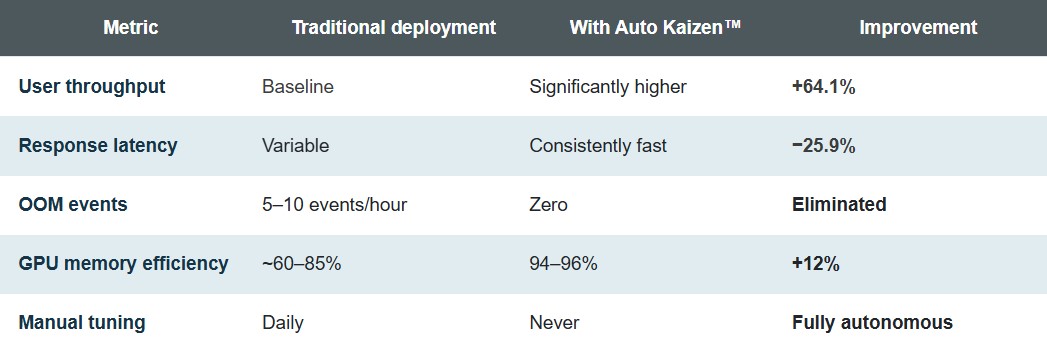
Proven Performance Gains
Metric
Traditional deployment
With Auto Kaizen™
Improvement
User throughput
Baseline
+64.1%
Response latency
Variable
Consistently fast
−25.9%
OOM events
Zero
Eliminated
GPU memory efficiency
94–96%
+12%
Manual tuning
Never
Fully autonomous
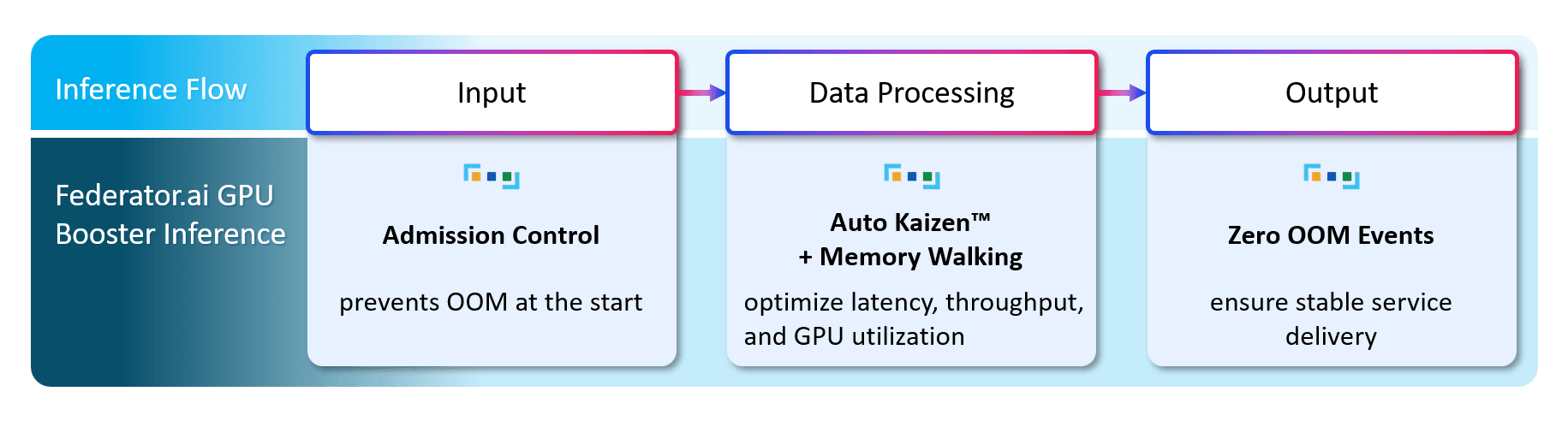
Simplified Inference Flow with Federator.ai GPU Booster Inference™ Enhancements