
Overview
Federator.ai GPU Booster Inference—with native support for DeepSeek-R1 and NVIDIA GPUs—delivers zero-downtime, high-performance LLM inference by replacing fragile, static settings with continuous, autonomous optimization. It significantly increases throughput, reduces latency variability, eliminates OOM (out-of-memory) failures, and safely drives GPU memory utilization into the mid-90% at enterprise scale.
Advanced Technologies Behind
Auto Kaizen™
Continuously runs a Plan–Do–Check–Act cycle to tune a substantial set of parameters—batch size, caching, scheduling, and memory management—using live metrics.
Zero-OOM multi-layer protection
Predictive admission control, ML-based memory forecasting, token-budget management, and intelligent preemption eliminate out-of-memory failures.
Memory Walking Technology
Proprietary control safely pushes GPU memory utilization to ~95–96%, well above the conservative 80–85% typical in static deployments, while staying OOM-free.
4-level observability
End-to-end visibility across Theoretical, Model, Service, and User TPS pinpoints where throughput drops between levels and confirms that model- or service-layer improvements result in measurable user gains.
Benefits of Federator.ai GPU Booster Inference
Higher Throughput & Lower Latency
Zero-Downtime Reliability
Max GPU ROI
Predictable, Fast Rollout
API-compatible with existing inference stacks and observable out of the box; production-ready in a few days.
Scales with Your Business
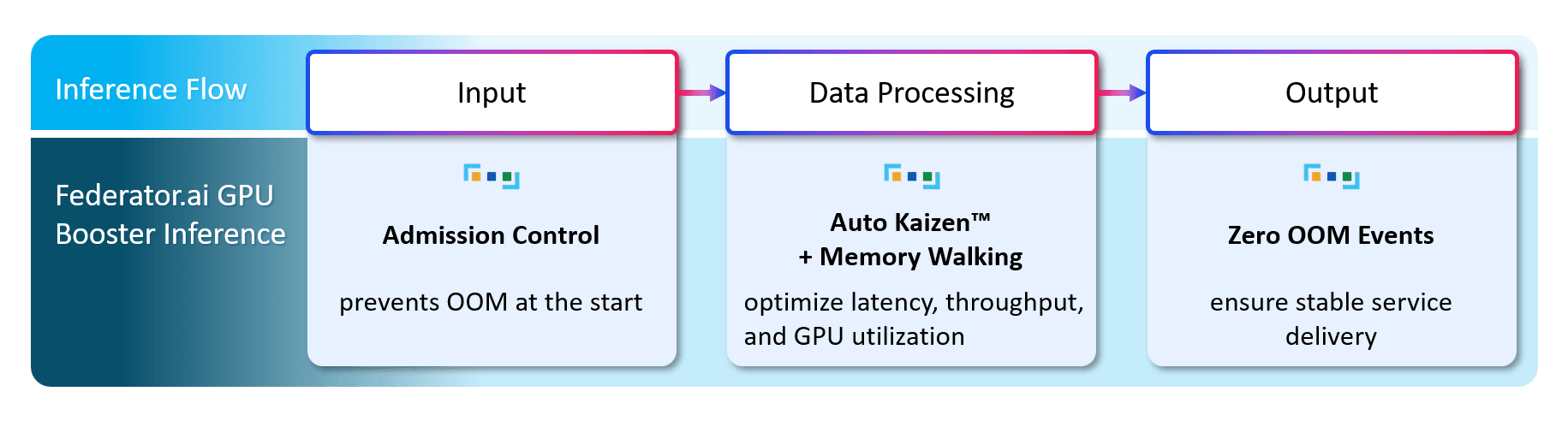
Figure: Simplified Inference Flow with Federator.ai GPU Booster Inference™ Enhancements