
Overview
In modern AI training, timing is everything. GPU workloads can spike in milliseconds, yet most liquid cooling systems take minutes to react. This lag creates a “timing gap” where hardware frequently exceeds its optimal temperature, leading to thermal throttling and reduced lifespan.
Federator.ai Smart Liquid Cooling (SLC) closes that gap. We transform the way modern AI data centers manage thermal efficiency by shifting from static, wasteful cooling to intelligent, workload-aware thermal optimization. Built to support high-density GPU infrastructure, this advanced solution dynamically adjusts liquid flow based on predictive heat modeling, not just simplistic GPU utilization metrics. Integrated seamlessly with Supermicro SCC and other standards-compliant infrastructure controllers, Federator.ai SLC enables continuous cooling optimization that conserves energy, preserves hardware lifespan, and accelerates AI performance.
Advanced Technologies Behind
Smarter Cooling with Correlated Insights
Workload-Aware Thermal Forecasting
Intelligent Pump Speed Control for Energy Savings
Closed-Loop Integration with Supermicro SCC
Benefits of Federator.ai Smart Liquid Cooling
Up to 30% Cooling Energy Savings
Up to 45% Compute Acceleration
Enhanced PUE and Sustainability
Extended Equipment Lifespan
Supports 250 kW-per-Rack Densities
Elastic to Workload Type
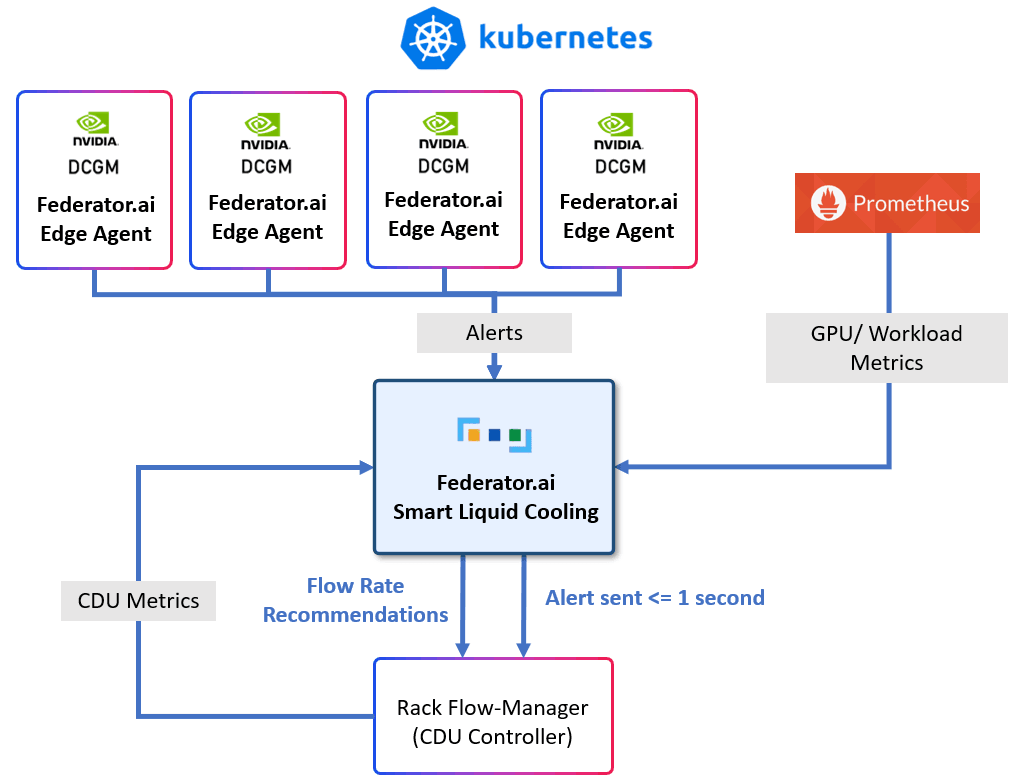
Figure: How Federator.ai SLC collects metrics and alerts to deliver timely alerts and optimal recommendations to CDU controllers