
What Predictive Self-Driving Autoscaling Is About
Reactive autoscaling reacts after the fact and often causes performance hits or wasted capacity. Predictive self-driving autoscaling plans capacity before demand moves. It weighs operational cost (how much capacity you run) against transition cost (how much you change between steps) to chart the lowest-cost scaling path over a forecast horizon. It then produces capacity targets for each upcoming interval and the scale actions to reach them, integrating with Kubernetes HPA/VPA, VMware, and cloud autoscaling groups so capacity is in place when it’s needed, not after.
How Predictive Self-Driving Autoscaling Works
Forecast demand
Use recent patterns to estimate demand for the next few intervals (e.g., the next 30–60 minutes).
Set priorities
Tell the system what matters more: the cost of running extra capacity vs. the cost of changing size too often. Add simple limits like minimum/maximum size and cooldowns.
Plan the path
For each upcoming interval, the system compares many possible capacity plans and picks the one with the lowest total cost—enough to stay fast, but without constant resizing.
Produce targets and actions
For each upcoming interval, output the target capacity and the delta from the prior step; map to pods/VMs, vCPU-GB, GPUs, or other units.
Keep it on track
Every few minutes it refreshes the forecast and updates the plan. Built-in safeguards prevent flapping and fall back to reactive rules if forecasts are missing.
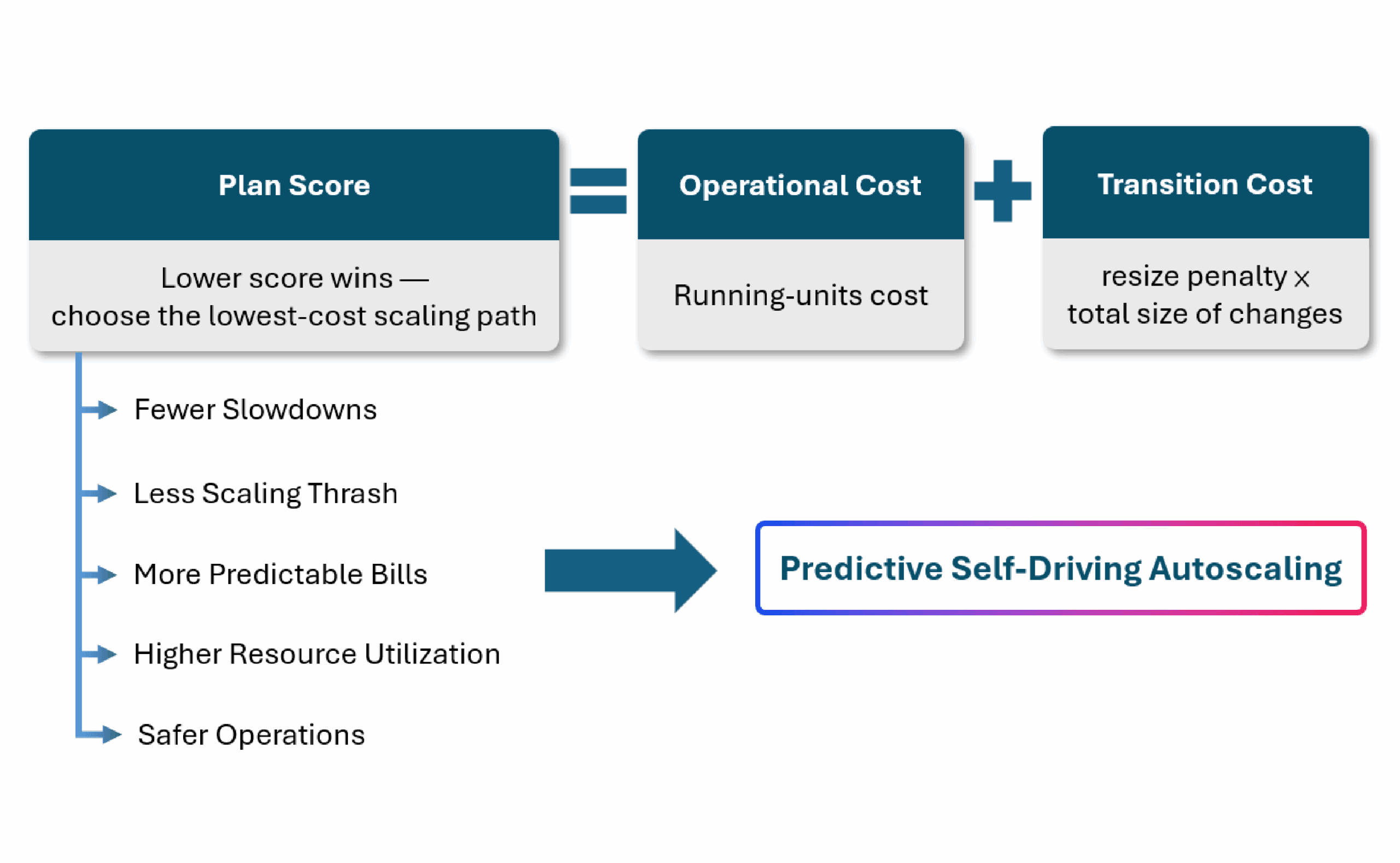
Figure: Lowest-cost scaling path for predictive self-driving autoscaling