
Managing multi-cluster applications manually is complex and error-prone. Sizing at only one layer wastes budget or causes slowdowns. This patent solves this by modeling how application workloads cascade through your entire stack—from the app down to the cluster node. By forecasting primary workloads and their corresponding sub-workload demands, it intelligently pre-allocates GPU/CPU, memory, and network resources across layers. This bridges the gap between engineering precision and fiscal efficiency, delivering a truly autonomous infrastructure that slashes hidden operating costs and eliminates operational risk across on-prem and cloud environments.
The Challenge of IT/Cloud Operations
Traditional monitoring sees symptoms. Multi-Layer Correlation finds causes.
Reactive by Default
Siloed Visibility
Over-Provisioning Waste
Without accurate prediction, teams over-allocate “just in case” — inflating infrastructure costs while still missing sudden demand surges. The result is both expensive and unreliable.
What It Is
Multi-Layer Correlation is ProphetStor’s patented method for mapping the causal relationships between application workloads, sub-application behavior, and infrastructure resources — and using those maps to predict what will be needed next, before demand arrives.
Instead of monitoring each component independently, the technology measures how changes at each layer influence the others — using cosine similarity across three-point time windows to identify which resources are most tightly coupled to workload changes. The result is a living causal model of your entire stack.
Layer 1 — Main Application Workload
The system continuously tracks how much work the main application receives — measured as request volume per unit time. A time-series model (ARIMA) forecasts workload at T+1 before it arrives. This is the top-level signal that drives all downstream decisions.
Layer 2 — Sub-Application Behavior
Layer 3 — Infrastructure Resources
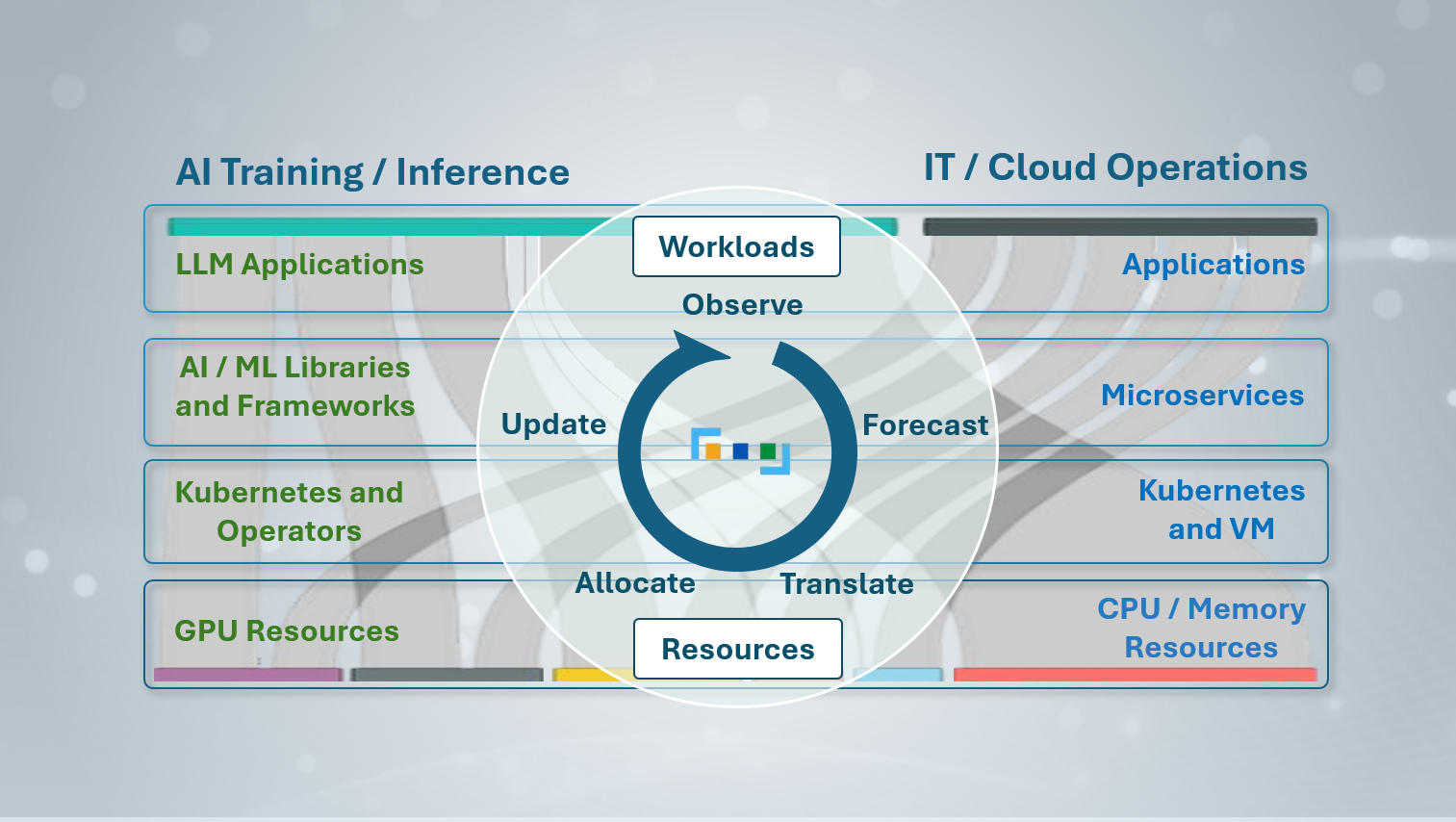
Patented Multi-Layer Correlation Mechanism Applied to GPU and IT/Cloud Resource Management | ProphetStor
How It Works
Four automated steps, running continuously — no manual intervention required.
STEP 01 · COLLECT
Continuous Data Collection
Workloads and resource usage across all nodes are collected at regular intervals. First and second correlation values between layers are calculated in real time from three-point time windows to capture live infrastructure dependencies.
STEP 02 · CORRELATE
Cascade Causal Analysis
Cosine similarity identifies which physical resources are highly correlated (above 0.5 threshold) with upper-level workload changes, dynamically ranking sub-applications by importance weight to guarantee SLA priority under constrained capacity.
STEP 03 · PREDICT
Predictive Resource Modeling
A advanced usage amount model (utilizing Regression and Bayesian Learning) forecasts precise resource increments for future intervals, seamlessly driven by historical patterns and the AI-predicted application workload trend.
STEP 04 · DEPLOY
Automatic Allocation
Additional capacity is provisioned and distributed to sub-applications by correlation weight, ensuring the highest-impact components get immediate priority. Fully automated: enables autonomous runtime execution, eliminating manual intervention and threshold tuning.
Why It Matters
Proactive
Full-Stack
Precise
Only high-correlation resources adjusted — no waste
Automated
Traditional monitoring tells you what happened. ProphetStor’s Multi-Layer Correlation tells you what’s about to happen — and acts on it automatically.
The causal intelligence this patent provides is the foundation of the entire ProphetStor stack. Without understanding why resources are demanded, accurate GPU placement and cost-optimized autoscaling are impossible. Multi-Layer Correlation is what makes the other two patents work.
For AI training clusters, ERP systems, and Kubernetes microservices — any environment where sub-component behavior drives infrastructure load — this distinction between reactive monitoring and proactive causal intelligence is the difference between SLA compliance and SLA failure.
Conventional Monitoring v.s. ProphetStor
Conventional Monitoring Approach
Monitors each layer independently — metrics in silos
Reactive: alerts fire after the problem has already occurred
No cross-layer causality — can’t explain why a sub-component is stressed
Resource allocation requires manual judgment and IT experience
Predicts at individual component level — misses cascade effects
ProphetStor Multi-Layer Correlation (patented)
✓
Correlates all layers together — one unified causal model
✓
Proactive: resources provisioned before the demand spike arrives
✓
Causal Analysis traces sub-application behavior to infrastructure load
✓
Fully automated allocation by correlation weight — no manual judgment
✓
Cascade prediction: workload at top accurately predicts infra needs at bottom
Where It Applies
ProphetStor was granted a U.S. patent for the method of optimizing resource allocation based on prediction with reinforcement learning. The patent covers demand forecast integration, possible operation cost (POC) calculation with dynamic programming, selective path pruning, and automated execution — across GPU, CPU, memory, I/O throughput, response time, requests per second, and latency. Integrates natively with Kubernetes HPA/VPA, VMware, and major cloud autoscaling services.
AI / ML infrastructure
Training & inference pipelines
Enterprise systems
ERP and business-critical apps
ERP systems run dozens of sub-applications that spike unpredictably during month-end close or peak business cycles. Proactive resource allocation prevents the system slowdowns that cost millions per hour of downtime.
Cloud & Kubernetes
Containerized microservices
In Kubernetes environments, sub-applications share node resources. The correlation model distributes node additions by impact weight — highest-correlation sub-components get priority when additional capacity is provisioned.
U.S. Patent: Multi-Layer Correlation
ProphetStor was granted a U.S. patent for the method of establishing system resource prediction and resource management models through multi-layer correlations. The patent covers the full pipeline: continuous multi-layer data collection, cosine-based cross-layer correlation analysis with threshold filtering, ARIMA time-series workload forecasting, ML-based predictive resource modeling, and automated node deployment with importance-weight-based sub-application allocation.
Frequently Asked Questions
What is Multi-Layer Correlation in AIOps?
ProphetStor’s patented method for mapping the causal relationships between application workloads, sub-application behavior, and infrastructure resources — and using those maps to predict precise resource demands before they arrive. Instead of monitoring each component independently in silos, Multi-Layer Correlation measures how changes at each layer cascade through the full stack, producing a living causal model of your entire GPU or cloud infrastructure. This technology is legally protected by U.S. Patent US11579933B2.
How does Multi-Layer Correlation differ from traditional infrastructure monitoring?
What are the three layers analyzed by this patented technology?
(1) Main Application Workload — the system tracks request volume per unit time and uses an ARIMA time-series model to forecast workload at T+1 before it arrives;
(2) Sub-Application Behavior — the main application’s constituent components—such as HTTP servers (NGINX), databases, messaging queues (Kafka), or search engines— are measured for their correlation with the main workload, with importance weights assigned based on sensitivity to demand changes;
(3) Infrastructure Resources — GPU, CPU cores, memory, network bandwidth, and storage are tracked at the node level. Only resources with a correlation value above 0.5 are adjusted, eliminating noise and focusing on what actually drives performance.
How does the predictive resource modeling work under the hood?
What is the role of Multi-Layer Correlation in an AI Factory?
What platforms, environments, and enterprise integrations are supported?
AI/ML Infrastructure: GPU clusters running distributed training workloads and high-throughput inference on platforms like NVIDIA DGX Cloud.
Cloud-Native & Kubernetes: Microservices sharing node resources, with direct integration into Kubernetes HPA/VPA, Datadog, Sysdig, and Prometheus.
Enterprise & Virtualization: High-density ERP systems running on VMware vSphere or major public clouds (AWS EC2, Azure VM, Google Compute Engine). It supports on-premises, public cloud, and hybrid deployments.
Is ProphetStor’s Multi-Layer Correlation technology patented?
Yes. ProphetStor was granted U.S. Patent US11579933B2 for its groundbreaking “Method for establishing system resource prediction and resource management model through multi-layer correlations.” The granted patent comprehensively covers the full automation pipeline: continuous multi-layer metric data collection, cosine-based cross-layer correlation analysis, threshold filtering, ARIMA workload forecasting, ML-based predictive resource modeling, and automated node deployment with importance-weight allocation. You can view the full legal filing and claims directly on Google Patents.